Oracle DBA Journey to Cloud, DevOps and Big Data..
Amit Bansal
Experienced professional with 16 years of expertise in database technologies. In-depth knowledge of designing and implementation of Disaster Recovery / HA solutions, Database Migrations , performance tuning and creating technical solutions.
Skills: Oracle,MySQL, PostgreSQL, Aurora, AWS, Redshift, Hadoop (Cloudera) , Elasticsearch, Python
Itertools is a powerful module and is part of python standard library. It provides a set of fast and memory efficient functions. You can learn more about them by referring to this article.
I have used following code to get the expected output
import pprint
pp = pprint.PrettyPrinter(indent=4)
from itertools import groupby
from operator import itemgetter
# Define group by key
grouper = itemgetter("id", "name")
result = []
#itertools requires sorted input, so we will first sort the input data
for key, grp in groupby(sorted(data, key = grouper), grouper):
temp_dict = dict(zip(["id", "name"], key))
temp_dict['child'] = []
# Use list comprehension to collect all the items in grp
temp_dict['child'] = list(item['child'] for item in grp)
result.append(temp_dict)
# print the result
pp.pprint(result)
Amazon Redshift is fully managed Cloud Datawarehouse from AWS for running analytic workloads. Lot of customers have requirements to encrypt data in transit as part of security guidelines. Redshift provides support for SSL connections to encrypt data and server certificates to validate the server certificate that the client connects to.
Before we proceed how SSL works with Redshift, lets understand why we need SSL. SSL is required to encrypt client/server communications and provides protection against three types of attack:
Eavesdropping – In case of un-encrypted connections, a hacker could use network tools to inspect traffic between client and server and steal data and database credentials. With SSL, all the traffic is encrypted.
Man in the middle (MITM) – In this case a hacker could hack DNS and redirect the connection to a different server than intended. SSL uses certificate verification to prevent this, by authenticating the server to the client.
Impersonation – In this hacker could use database credentials to connect to server and gain access to data. SSL uses client certificates to prevent this, by making sure that only holders of valid certificates can access the server.
You can easily enable SSL on Amazon Redshift Cluster by setting require_ssl to True in Redshift parameter group.
In this blog post, I would discuss 3 sslmode settings – require, verify-ca, and verify-full , through use of psql and python.
Setup details
I have a Amazon Redshift cluster with publicly accessible set to “No” and I would be accessing it via my local machine. Since database is in private subnet, I would need to use port forwarding via bastion host. Make sure this bastion host ip is whitelisted in Redshift security group to allow connections
## Add the key in ssh agent
ssh-add <your key>
## Here bastion host ip is 1.2.3.4 and we would like to connect to a redshift cluster in Singapore running on port 5439. We would like to forward traffic on localhost , port 9200 to redshift
ssh -L 9200:redshift-cluster.xxxxxx.ap-southeast-1.redshift.amazonaws.com:5439 [email protected]
When we enable require_ssl to true, we have instructed Redshift to allow encrypted connections. So if any client tries to connect without SSL, then those connections are rejected. To test this , let’s modify sslmode settings for psql client, by setting PGSSLMODE environment variable.
export PGSSLMODE=disable
psql -h localhost -p 9200 -d dev -U dbmaster
psql: FATAL: no pg_hba.conf entry for host "::ffff:172.31.xx.9", user "dbmaster", database "dev", SSL off
As we can see, all database connections are rejected. Let’s now discuss SSL mode – require, verify-ca, and verify-full
1. sslmode=require
With sslmode setting of require, we are telling that we need a encrypted connection. If a certificate file is present, then it will also make use of it to validate the server and behavior will be same as verify-ca. But if the certificate file is not present, then it won’t complain (unlike verify-ca) and connect to Redshift cluster.
export PGSSLMODE=require
psql -h localhost -p 9200 -d dev -U dbmaster
psql (11.5, server 8.0.2)
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
We can see that psql has made a SSL connection and is using TLS 1.2.
2. sslmode=verify-ca
If we use, verify-ca, then the server is verified by checking the certificate chain up to the root certificate stored on the client. At this point, we need to also give Redshift certificate which has tobe be downloaded from download link provided in Amazon Redshift documentation. To demonstrate, that we really need a certificate, let’s try connecting without certificate
export PGSSLMODE=verify-ca
psql -h localhost -p 9200 -d dev -U dbmaster
psql: error: could not connect to server: root certificate file "/Users/amit/.postgresql/root.crt" does not exist
Either provide the file or change sslmode to disable server certificate verification.
psql is complaining that it couldn’t find the certificate and we should either provide ssl certificate or change sslmode settings. Let’s download the certificate and store under home directory
mkdir ~/.postgresql
cd .postgresql
curl -o root.crt https://s3.amazonaws.com/redshift-downloads/redshift-ca-bundle.crt
After downloading certificate , and placing under the desired directory, our connection attempt succeeds
3. sslmode=verify-full
Next, if we want to prevent Man in the Middle Attack (MITM), we need to enable sslmode=verify-full . In this case the server host name provided in psql host argument will be matched against the name stored in the server certificate. If hostname matches, the connection is successful, else it will be rejected.
export PGSSLMODE=verify-full
psql -h localhost -p 8192 -d dev -U awsuser
psql: error: could not connect to server: server certificate for "*.xxxxxx.ap-southeast-1.redshift.amazonaws.com" does not match host name "localhost"
In our test connection fails, as we are using port forwarding and localhost doesn’t match the redshift hostname pattern
What this means is that if you use any services like route53 to have friendly names, verify-full won’t work as the hostname specified in psql command and host presented in certificate don’t match. If your security team is ok with verify-ca option, then you can revert to that setting, else you will have to get rid of aliases and use actual hostname.
In my case, I can resolve the error by connecting to Redshift Cluster from bastion host (instead of my local host tunnel setup) and using psql command with actual hostname
psql -h redshift-cluster.xxxxxx.ap-southeast-1.redshift.amazonaws.com -p 5439 -d dev -U dbmaster
SSL Connection using Python
Next, let’s see how you can connect to Redshift cluster using python code. This is useful, if you have Lambda code or other client applications which are written in Python. For this example, we will use PyGreSQL module for connecting to Redshift Cluster.
$ python
Python 3.7.9 (default, Aug 31 2020, 12:42:55)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pgdb
>>> rs_port =5439
>>> rs_user = 'dbmaster'
>>> rs_passwd='****'
>>> rs_dbname = 'dev'
>>> rs_host='redshift-cluster.xxxxx.ap-southeast-1.redshift.amazonaws.com'
>>> rs_port =5439
>>> conn = pgdb.connect(dbname=rs_dbname,host=rs_host,port=rs_port , user=rs_user, password=rs_passwd,sslmode=rs_sslmode)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/ec2-user/miniconda3/envs/venv37/lib/python3.7/site-packages/pgdb.py", line 1690, in connect
cnx = _connect(dbname, dbhost, dbport, dbopt, dbuser, dbpasswd)
pg.InternalError: root certificate file "/home/ec2-user/.postgresql/root.crt" does not exist
Either provide the file or change sslmode to disable server certificate verification.
Before running above code, I removed the certificate file to show that pgdb.connect requires SSL certificate. Let’s now add the certificate to non-default location like “/home/ec2-user/root.crt” and use sslrootcert argument to pass the location
This is short post on Timeout errors faced using custom libraries with AWS Glue Python shell job. I referred the steps listed in AWS docs to create a custom library , and submitted the job with timeout of 5 minutes. But the job timed out without any errors in logs. Cloudwatch log reported following messages
2020-06-13T12:02:28.821+05:30 Installed /glue/lib/installation/redshift_utils-0.1-py3.7.egg 2020-06-13T12:02:28.822+05:30 Processing dependencies for redshift-utils==0.1 2020-06-13T12:12:45.550+05:30 Searching for redshift-module==0.1 2020-06-13T12:12:45.550+05:30 Reading https://pypi.org/simple/redshift-module/
On searching for error, I came across this AWS Forum post ,where it was recommended to use python3.6. I referred back documentation and it confirmed that AWS Glue shell jobs are compatible with python 2.7 and 3.6. I was using python3.7 virtualenv for my testing, so this had to be fixed.
To easily manage multiple environments, I installed miniconda on my Mac which allows to create virtual environment with different python version. Post installation, I created a new python3.6 env with conda and created the egg file
MVCC (Multi-Version Concurrency Control) feature allows databases to provide concurrent access to data. This allows each SQL statement to see a snapshot of data as it was some time ago, regardless of the current state of the underlying data. This prevents statements from viewing inconsistent data produced by concurrent transactions performing updates on the same data rows, providing transaction isolation for each database session. To summarize “Readers don’t block writers and writers don’t block readers”
If you are coming from Oracle or MySQL background, you would be aware that during an update/delete ,DML activity will make changes to rows and use separate store called “Undo” to track the old image of data. If any other session want to get consistent image, then database uses undo to provide consistent snapshot of data. Like many other databases, PostgreSQL also supports MVCC but takes different approach to store the old changes.
In PostgreSQL, update or delete of a row (tuple in PostgreSQL) does not immediately remove the old version of the row. When you update a row, it will create a copy of the row with new changes and insert in the table. Then, it will update the old copy header to make it invisible for future transactions. Similarly for delete, it won’t delete the row but update metadata to make them invisible. Eventually, these old rows will no longer be required by transactions and will have to be cleaned up. This cleanup is handled by “Vacuum”. Note that apart from increasing the total database size, table or index bloat also impacts query performance as database need to process bigger objects.
=>vacuum table 'bloated_table';
If you run above command, it will remove dead tuples in tables and indexes and marks the space available for future reuse. But this will not release the space to operating system. As vacuum is manual approach, PostgreSQL has a background process called “Autovacuum” which takes care of this maintenance process automatically. Autovacuum process to delete rows is controlled by 2 parameters autovacuum_vacuum_threshold and autovacuum_vacuum_scale_factor (There are other parametes like autovacuum_freeze_max_age which can trigger autovacuum)
vacuum threshold = autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor * number of tuples
You can find this values by querying pg_settings. For RDS, autovacuum_vacuum_threshold is 50 rows and autovacuum_vacuum_scale_factor is 0.1 i.e 10% of the table size.
select name,setting from pg_settings where name in ('autovacuum_vacuum_threshold','autovacuum_vacuum_scale_factor'); name | setting --------------------------------+--------- autovacuum_vacuum_scale_factor | 0.1 autovacuum_vacuum_threshold | 50
This means that if there is table with 100 M rows, you should have ~10M changes ( 50+0.1*100M ) before autovacuum is triggered. Additionally, there are limited number of autovacuum worker processes and if autovacuum is not tuned properly, table could have much higher dead rows. It’s advisable to reduce the scale factor to lower value, either at table level or at database level to prevent bloat. You would also need to tune the autovacuum process settings to improve the cleanup process. There is an excellent blog article titled “A Case Study of Tuning Autovacuum in Amazon RDS for PostgreSQL” on AWS database blog which helps to tune autovacuum.
If you wish to reclaim OS space, then you need to execute “Vacuum Full” which will compact tables by writing a complete new version of the table file with no dead tuples. But this comes at a cost. Vacuum full requires “Exclusive lock” on the table and blocks any DML on the table, leading to downtime. This can be problematic as large tables with multiple indexes can take really long time (7-8 hours) to rebuild.
Enter pg_repack !! This utility helps to perform Full vacuum without downtime by making use of trigger to take care of changes happening on parent table. Below table compares the internal working on Table vs Index rebuilds
Table Rebuild
Index Rebuild
To perform a full-table repack, pg_repack will:
1. create a log table to record changes made to the original table 2. add a trigger onto the original table, logging INSERTs, UPDATEs and DELETEs into our log table 3.create a new table containing all the rows in the old table 4. build indexes on this new table 5. apply all changes which have accrued in the log table to the new table 6. swap the tables, including indexes and toast tables, using the system catalogs 7. drop the original table
pg_repack will only hold an ACCESS EXCLUSIVE lock for a short period during initial setup (steps 1 and 2 above) and during the final swap-and-drop phase (steps 6 and For the rest of its time, pg_repack only needs to hold an ACCESS SHARE lock on the original table, meaning INSERTs, UPDATEs, and DELETEs may proceed as usual.
To perform an index-only repack, pg_repack will:
1. create new indexes on the table using CONCURRENTLY matching the definitions of the old indexes 2. swap out the old for the new indexes in the catalogs 3. drop the old indexes
Let’s use pg_repack to clear this bloat. To use pg_repack, you need to install extension and a client utility. RDS PostgreSQL supports pg_repack for installations having version of 9.6.3 and higher.Extension version will differ depending on your RDS PostgreSQL version. e.g RDS PostgreSQL 9.6.3 installs pg_repack 1.4.0 extension, whereas 9.6.11 installs pg_repack 1.4.3 extension.
To create extension, connect as master user for RDS database and run create extension command,
postgres=> create extension pg_extension; postgres=> \dx pg_repack List of installed extensions Name | Version | Schema | Description -----------+---------+--------+-------------------------------------------------------------- pg_repack | 1.4.3 | public | Reorganize tables in PostgreSQL databases with minimal locks
To install pg_repack client, download the tar bar from here and build the utility. You need to ensure that extension and client utility version matches. pg_repack provides option to perform full vacuum at table level, index level or table+index . If you want to perform vacuum full for table and associated indexes, then it can be done by using below statement
-k flag is important as RDS master user does not have Postgresql superuser role and omitting this option leads to error “ERROR: pg_repack failed with error: You must be a superuser to use pg_repack”
Above statement will create new indexes and will drop the older indexes after all indexes are recreated. If you are performing this action on really big tables, it will take time and will slow down DML activity on the table as you will have 2*n-1 indexes before last one is created (n=number of indexes).Therefore, if there are multiple indexes on the table, it would be better to recreate index one by one using –index clause
In my scenario, I went with table+index vacuum option.After rebuild, actual table size reduction was 10% instead of 24% and for index , it was 75% instead of 85%. As you can see, there could be 10-20% variance between actual object size (post vacuum) vs estimated size. Therefore, it would be good to carry out testing in clone environment before committing on size savings.
Object Name
Original Size
Estimated Size after removing bloat Size
Actual size after rebuild
bloated
30GB
23GB
27G
pkey_bloated
64GB
10GB
16GB
Pg_repack creates the objects under repack schema and later moves it to the correct schema. To monitor the pg_repack session, use pg_stat_activity view
select * from pg_stat_activity where application_name='pg_repack'
Oracle Goldengate supports Oracle to PostgreSQL migrations by supporting PostgreSQL as a target database, though reverse migration i.e PostgreSQL to Oracle is not supported. One of the key aspect of these database migrations is initial data load phase where full tables data have to copied to the target datastore. This can be a time consuming activity with time taken to load varying based on the table sizes. Oracle suggests to use multiple Goldengate processes to improve the database load performance or to use native database utilities to perform faster bulk-loads.
To use a database bulk-load utility, you use an initial-load Extract to extract source records from the source tables and write them to an extract file in external ASCII format. The file can be read by Oracle’s SQL*Loader, Microsoft’s BCP, DTS, or SQL Server Integration Services (SSIS) utility, or IBM’s Load Utility (LOADUTIL).
Goldengate for PostgreSQL doesn’t provide native file loader support like bcp for MS SQL and sqlloader for Oracle. As an alternative, we can use FORMATASCII option to write data into csv files (or any custom delimiter) and then load them using PostgreSQL copy command .This approach is not automated approach and you will have to ensure that all files are loaded into target database.
In this post, we will evaluate 2 approaches i.e using Multiple replicat Processes and using ASCII dump files with PostgreSQL copy command to load data and compare their performance. Below diagram shows both the approaches
create sequence scott.big_table_seq start with 1 increment by 1 cache 500 nomaxvalue; -- Load data INSERT /*+ APPEND */ INTO scott.Big_table SELECT scott.big_table_seq.nextval AS id, TRUNC(DBMS_RANDOM.value(1,5)) AS small_number, TRUNC(DBMS_RANDOM.value(100,10000)) AS big_number, DBMS_RANDOM.string('L',TRUNC(DBMS_RANDOM.value(10,50))) AS short_string TRUNC(SYSDATE + DBMS_RANDOM.value(0,366)) AS created_date FROM dual CONNECT BY level <= 10000; COMMIT;
INSERT /*+ APPEND */ INTO scott.Big_table SELECT scott.big_table_seq.nextval AS id, small_number, big_number, short_string, long_string, created_date FROM scott.Big_table; COMMIT;
Approach 1 : Using Oracle Goldengate multiple replicat processes to load data
In this approach, I used multiple Oracle Goldengate Replicat processes (8) using @range filter to load data into PostgreSQL.
We were able to get 5k inserts/sec per thread and were able to load the table in ~88 mins with 8 replicat processes. One key point to remember is that if you are working with EC2 and RDS databases, you should have EC2 machine hosting trail files and RDS instance in same AZ. During the testing, we noticed that insert rate dropped drastically (~800 insert per sec) when using cross AZ writes. Below is replicat parameter file used for performing data load.
You will need to create additional replicat process files by making change to the range clause.e.g FILTER (@RANGE (2,8)), FILTER (@RANGE (3,8)), etc.
Approach 2: Data load using PostgreSQL copy command
In second approach, we used parameter file with FORMATASCII option(refer to below snippet) for creating a Goldengate Extract process which dumped the data with ‘|’ delimiter and then used PostgreSQL copy command to load data from these dump files.
With above parameter file, Goldengate Extract process would send data to remote system and store the data in dump files. These files are then loaded into PostgreSQL using \copy command.
psql> \copy scott.big_table from '/fs-a01-a/databases/ggate/initload/i4000000' with DELIMITER '|';
Data load took 21 mins, which is nearly 4x faster than initial approach. If you remove the Primary key index, then it drops the time taken to ~9 mins to load 200M POC table.
Update:
Oracle GoldenGate 19.1 comes with DataDirect 7.1 PostgreSQL Wire Protocol ODBC driver for PostgreSQL connectivity. You can now add a parameter “BatchMechanism=2” to speed up the inserts. After setting this parameter, odbc driver will start batching inserts into memory buffer and will insert them together instead of single row inserts. You can find details here
To add the parameter, update odbc.ini and add BatchMechanism under the database section
In my testing, I saw that insert rate increased from 5.3K rows per second to 35K i.e nearly 7x increase. I also noticed that WriteIOPS on this Aurora Instance increased from 20K to 80-100K IOPS
In this post, we would understand what are reserved instances, when do you need them and various ways to monitor them in your environment.
As more enterprises are embracing AWS cloud technologies, we need to understand AWS’s breadth of services and pricing options to right size our compute resources and run efficient infrastructure. Cost optimization is one of the 5 pillars of AWS Well-Architected Framework, a framework developed by AWS to help cloud architects build secure, high-performing, resilient, and efficient infrastructure for their applications. If you would like to read more about the Cost optimization pillar, you can refer to this whitepater.
Introduction
Reserved Instance(RI) is a billing concept which provides pricing discounts for your running instances in AWS accounts to help lower costs. In case of EC2, they also provide capacity reservation i.e AWS will ensure that you always have access to EC2 capacity when you need it, for as long as you need it . The discounted usage price is fixed for the term of the RI, allowing you to predict costs over the term of the reservation. If you are expecting consistent heavy use (e.g., Database Services), RIs can provide significant cost savings as compared to using On-Demand instances. Important point to note is that RI is not a physical instance.i.e to achieve savings, you don’t have to modify your running instance.
When you purchase RI, the RI is automatically applied to running RDS/Redshift nodes with the same instance parameters (Region, Engine/Node Type, RDS DB Instance Class, and Instance Count). RI does not renew automatically; you can continue to use the RDS/Redshift instances/nodes without interruption, but you will be charged On-Demand rates if you do not have sufficient number of RI counts in your AWS account. RI can be visualised as discount coupons that can be applied to your final monthly bill.
Below table provides a list of parameters that you can set when purchasing RI. If there is mismatch in any of the parameter, RI discount will not be applied.
Database Type
RI Region
RI Type
RI Class
RI Count
Amazon RDS
Region
Engine Type
DB Instance Class
Instance Count
Redshift
Region
Node Type
Node Count
For example, let’s consider that you have been running 2 PostgreSQL RDS (r3.db.4xlarge) instances and 2 MySQL RDS (r3.db.4xlarge) instances in us-east-1 since December 2017. On January 1 2018, you purchased RI for 3 PostgreSQL r3.db.4xlarge instances in us-east1. At the end of January 2018, your monthly bill would include RDS RI discount on 2 PostgreSQL RDS instances since you only have 2 running PostgreSQL RDS instances in us-east-1 region. As a result, your January 2018 monthly bill would include 2 MySQL RDS with On-Demand rate and 1 unused RI available for RDS PostgreSQL database engine (see Table 2).
Region
Engine Type
DB Instance Class
Running Instance
RI Available
RI Applied
us-east-1
PostgreSQL
db.r3.4xlarge
2
3
2
us-east-1
MySQL
db.r3.4xlarge
2
0
0
In order to optimize your monthly billing for all the RDS instances, you would need to purchase additional RDS RI. To do so, you would purchase additional RI in us-east-1 with RDS MySQL database Engine Type, Instance type/size and count.
RDS Instance Size Flexibility
Amazon RDS Reserved Instances provide size flexibility for the MySQL, MariaDB, PostgreSQL, and Amazon Aurora database engines. With size flexibility, your RI’s discounted rate will automatically apply to usage of any size in the instance family (using the same database engine).
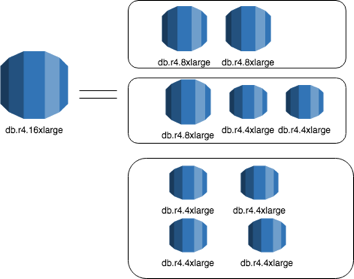
e.g If you are running a db.r4.8xlarge with corresponding RI ,and have now decided to upgrade to db.r4.16xlarge, then you can purchase reservation for 1 db.r4.8xlarge to avoid on-demand charges. Below diagram tries to depict that with 1 db.r4.16xlarge reservation, you can run multiple combinations – (2 db.r4.8xlarge ) or (4 db.r4.4xlarge) or (1 db.r4.8xlarge and 2 db.r4.4x.large).
AWS uses Normalized units to arrive at these calculations. The following table shows the number of normalized units for each DB instance size.
Instance Size
Single-AZ Normalized Units
Multi-AZ Normalized Units
micro
0.5
1
small
1
2
medium
2
4
large
4
8
xlarge
8
16
2xlarge
16
32
4xlarge
32
64
8xlarge
64
128
10xlarge
80
160
16xlarge
128
256
When to Purchase Reserved Instance?
In order to utilise Reservations optimally, buy RI instances if you plan to use resource for long duration. AWS provides 1-year and 3-year offerings along with option to pay No upfront, partial upfront and All Upfront and hourly rates varies based on the option chosen. You can refer to Redshift Pricing and RDS Pricing for the rates.
Note:- Redshift and RDS RI do not come with a capacity guarantee as they are only a billing discount.
Considering that these are fixed commitments, you will be charged regardless of usage. Therefore, if the resource is going to be short-lived or you are not sure if it’s the right instance type, then it would be recommended to use On-Demand instances. Also, if you need to upgrade capacity for short duration i.e say for 10 days in a calendar year, it would make sense to pay on-demand charges for that extra capacity rather than purchasing reservation. You can make use of AWS Simple Monthly Calculator to arrive at the total cost and make informed decision.
Monitoring
You should monitor your reservations as there could be mismatch which could impact your monthly bill. Mismatch could be due to following scenarios:
Scaling: In case of scaling activity like adding new RDS read replica or adding additional nodes to cluster (Redshift), new reservations need to be bought else there can be mismatch in Total running vs Total Reserved cluster.
Expired Reservations: Reservations have fixed term of 1 or 3 years and expire after completion of term. They are not auto-renewed which can lead to resources running with On-Demand pricing
I have listed below commands to get information about running and reserved resources (RDS and Redshift). You can also get this information from AWS console under the respective service.
This blog reflect our own views and do not necessarily represent the views of our current or previous employers.
The contents of this blog are from our experience, you may use at your own risk, however you are strongly advised to cross reference with Product documentation and test before deploying to production environments.







Recent Comments