You have been asked to schedule a shell script which need to connect to a particular user and perform some action? How do you pass the password to script without hardcoding it in script. If password is written in a script, isn’t it a security threat?
Well with 10gR2 , Oracle Wallet provides you with facility to store database credentials in client side Oracle Wallet. Once stored, you can connect to database using sqlplus /@connect_string
Let’s see how it works.
Create a Oracle Wallet Syntax – mkstore -wrl -create
$mkstore -wrl /u02/app/oracle/product/11.2.0/dbhome_1/network/admin/wallet
-create
Enter wallet password:
If you schedule cron through oracle user, keep the privileges as such. Please note that if a user has a read permission on these files, it can login to database.So it’s like your House Key which you would like to keep safely with you 🙂
Next step is to add database credential to the wallet. Before this, create a tnsnames entry you will use to access the database
$mkstore -wrl /u02/app/oracle/product/11.2.0/dbhome_1/network/admin/wallet
-createCredential amit_test11r2 amit amit
Enter wallet password:
To confirm, if the credential has been added , use listCredential option
$mkstore -wrl /u02/app/oracle/product/11.2.0/dbhome_1/owm/wallets/oracle
-listCredential
Oracle Secret Store Tool : Version 11.2.0.1.0 - Production
Copyright (c) 2004, 2009, Oracle and/or its affiliates. All rights reserved.
Enter wallet password:
List credential (index: connect_string username)
1: amit_test11r2 amit
Now add following entries in client sqlnet.ora file
Start Oracle Wallet manager $owm
To enable auto login:
1. Select Wallet from the menu bar.
2.Select Auto Login. A message at the bottom of the window indicates that auto login is enabled.
Now let’s try connecting to database
[oracle@db11g admin]$ sqlplus /@amit_test11r2
SQL*Plus: Release 11.2.0.1.0 Production on Tue Sep 8 23:34:37 2009
Copyright (c) 1982, 2009, Oracle. All rights reserved.
SQL> show user
USER is "AMIT"
We have been able to login without specifying a password. In case you change password for Database User, you will have to modify credentials .If you don’t, your DB login will fail with ORA-1017.
SQL> alter user amit identified by amitbansal;
User altered.
[oracle@db11g admin]$ sqlplus /@amit_test11r2
SQL*Plus: Release 11.2.0.1.0 Production on Tue Sep 8 23:35:34 2009
Copyright (c) 1982, 2009, Oracle. All rights reserved.
ERROR:
ORA-01017: invalid username/password; logon denied
To modify credential you need to use modifyCredential option. Syntax for command is
[oracle@db11g wallet]$ mkstore -wrl /u02/app/oracle/product/11.2.0/dbhome_1/network/admin/wallet/
-modifyCredential amit_test11r2 amit amitbansal
Oracle Secret Store Tool : Version 11.2.0.1.0 - Production
Copyright (c) 2004, 2009, Oracle and/or its affiliates. All rights reserved.
Enter wallet password:
Modify credential
Modify 1
To delete credentials use deleteCredential option with tnsalias
$mkstore -wrl /u02/app/oracle/product/11.2.0/dbhome_1/network/admin/wallet/
-deleteCredential amit_test11r2
Oracle Secret Store Tool : Version 11.2.0.1.0 - Production
Copyright (c) 2004, 2009, Oracle and/or its affiliates. All rights reserved.
Enter wallet password:
Delete credential
Delete 1
You can add more users to these wallet , but you will have to use a separate TNSALIAS for it. Note that TNSALIAS is a unique identifier for each user to connect to database.
As 11gR2 is out for Linux, I decided to upgrade one of my existing 10.2.0.3 database to 11.2.0.1 to get the look and feel of 11gR2. Direct upgrade to 11gR2 is supported from 9.2.0.8 or higher, 10.1.0.5 or higher, 10.2.0.2 or higher and 11.1.0.6 or higher. If you have a database 9.2.0.6 then first you need to upgrade to intermediate release i.e 9.2.0.8 then to 11.2.0.1.
I will discuss how to upgrade an existing Single Instance 10.2.0.3 database with ASM, having same ORACLE_HOME, to 11gR2 with ASM. The upgrade needs to be performed in two phases:
1. Upgrade the ASM instance
2. Upgrade the database
Upgrade ASM Instance: ===============
There are three ways to upgrade already existing ASM instance:
- Using OUI of Grid Infrastructure
- Using ASM Configuration Assistant
- Manual upgrade
The recommended method to upgrade ASM instance is to use OUI of Grid Infrastructure, which I have used .
STEP 1:
— Create OSASM group:
If you want, you can create a separate group for ASM instance here it is named as ASMADMIN.
# groupadd asmadmin
# usermod -a -G asmadmin oracle
STEP 2:
Before upgrading an ASM instance to 11gR2 it is mandatory to add a ‘user and password’ combination to the password file which is local to node’s ASM instance. Login to database instance “/ as sysdba”:
SQL> create user sood identified by oracle;
SQL> grant sysdba to sood;
SQL> select * from v$pwfile_users;
USERNAME SYSDB SYSOP
------------------------------ ----- -----
SYS TRUE TRUE
SOOD TRUE FALSE
STEP 3:
From 11gR2 onwards ASM is part of Grid Infrastructure and we need to download Grid Infrastructure software first. To download the software for 11gR2 Grid Infrastructure click here
Start the RunInstaller:
./runInstaller
Click on the Image to Enlarge.
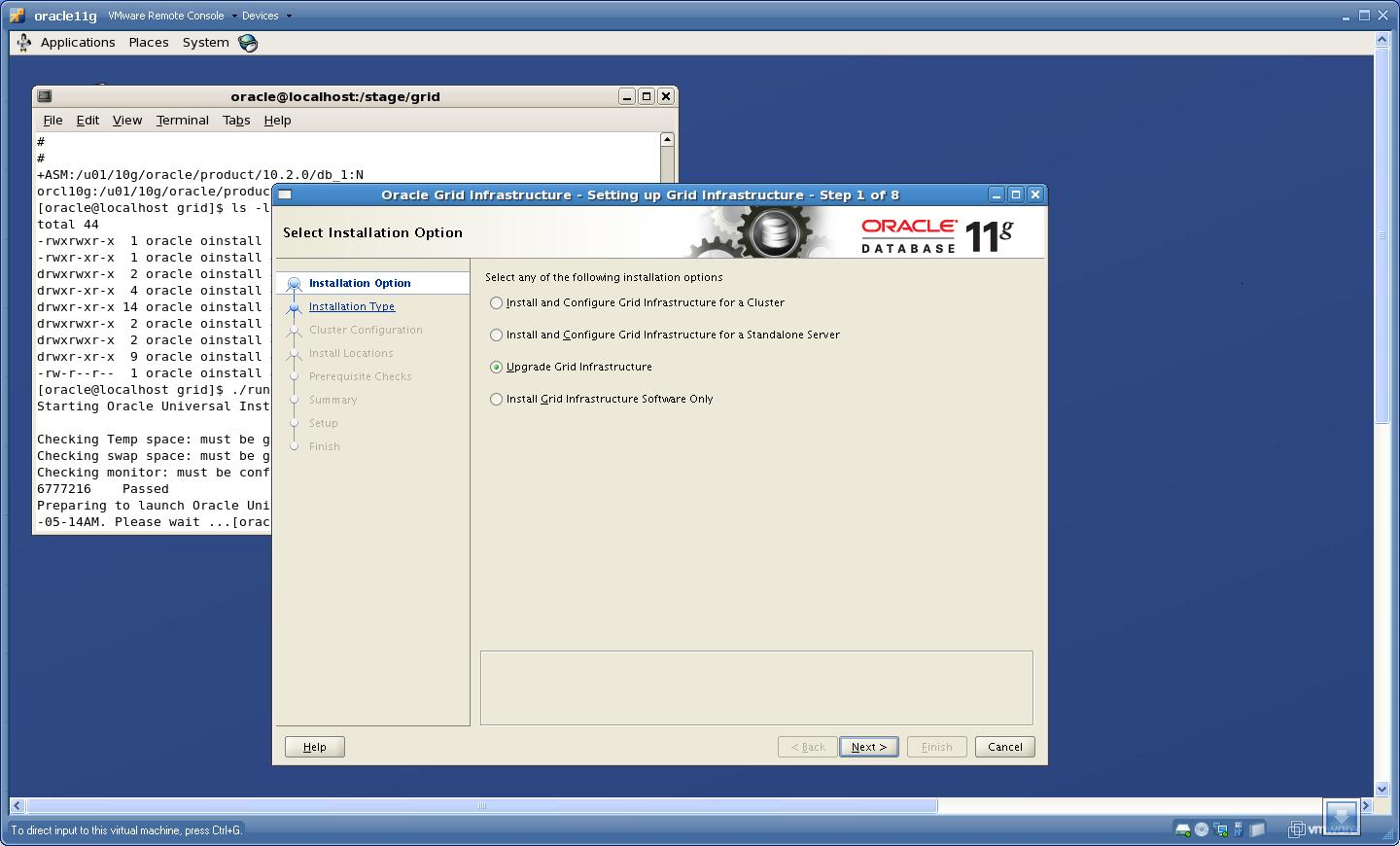
1. It will automatically defaults to the “Upgrade Mode”
Select “Upgrade Grid Infrastructure” and click Next.
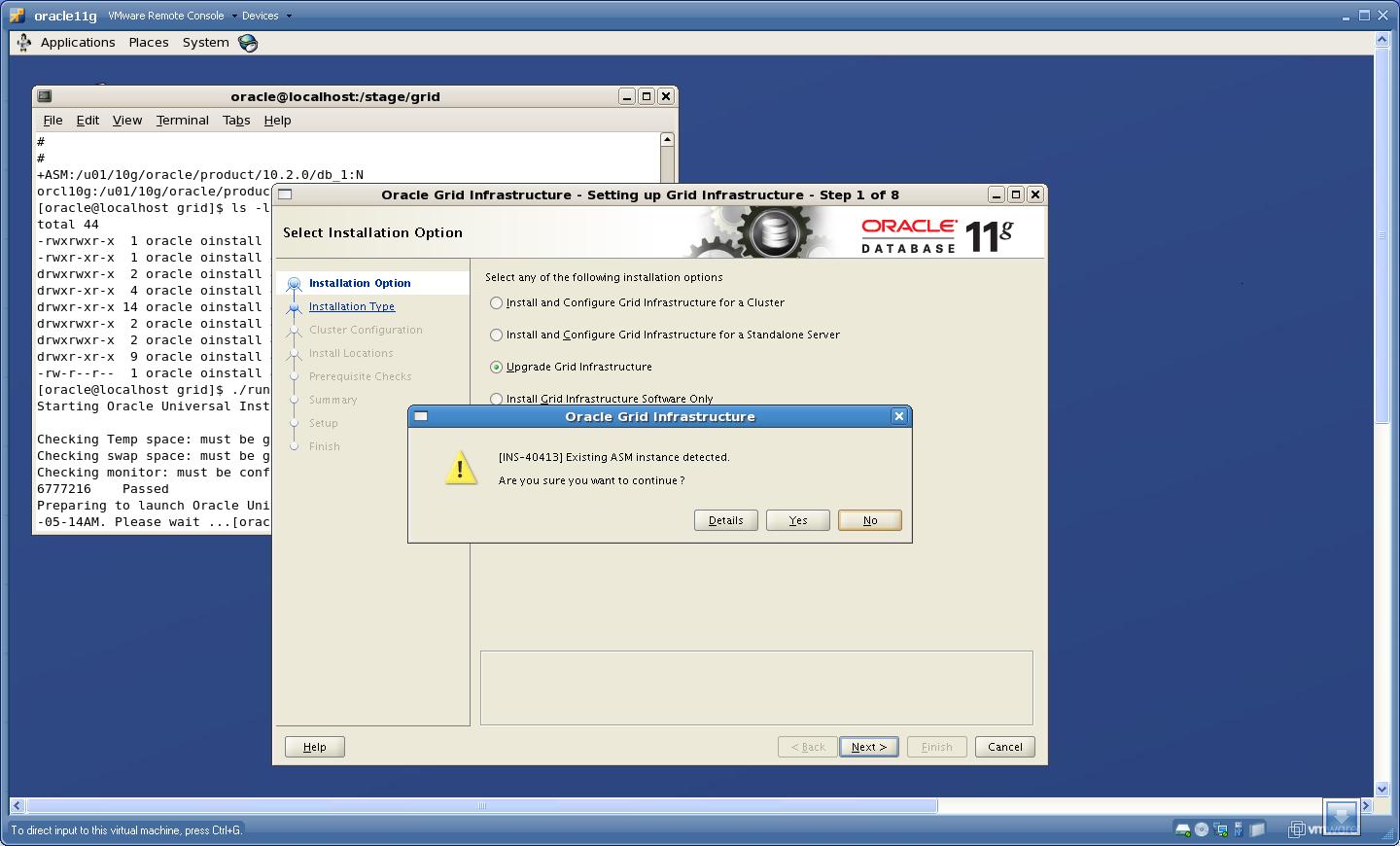
2. On clicking Next, It will detect the already existing ASM instance. Shutdown the Database and ASM instance at this point.
Click “Yes”.
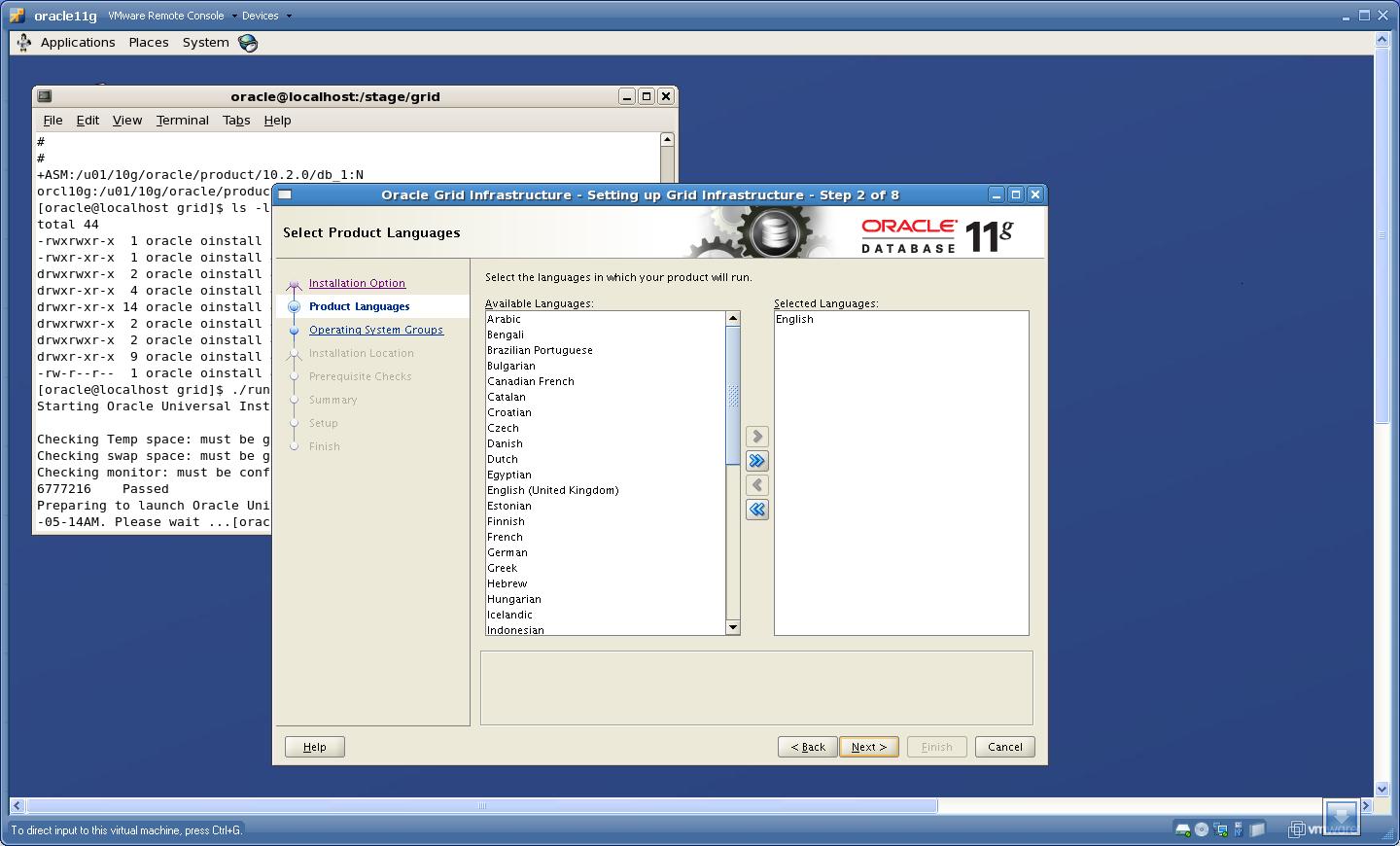
3. Select the Language
Click “Next”.
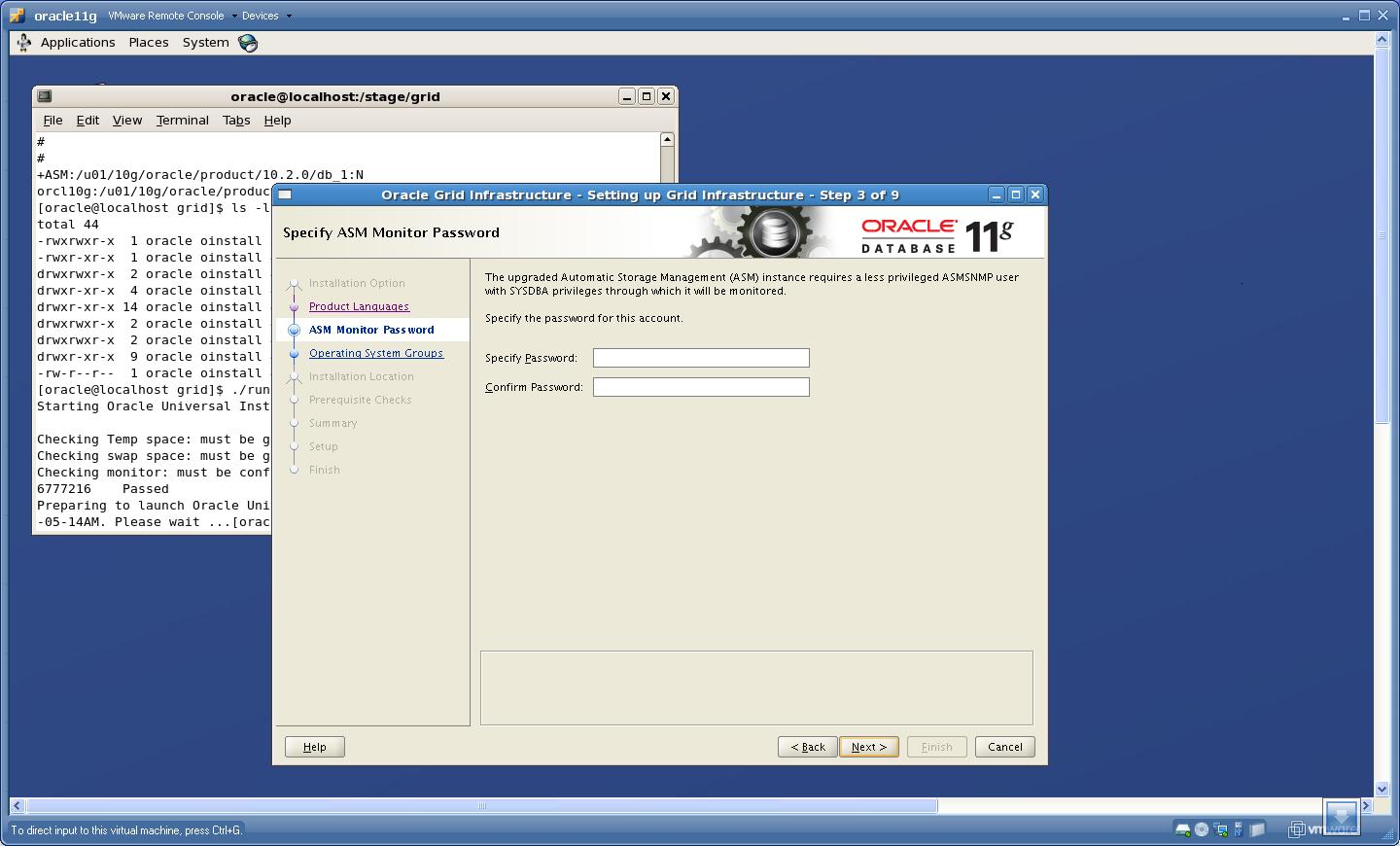
4. Enter a Password for ASMSNMP user. The password can be anything you want, though Oracle will ask you to set a password which adhers to Oracle’s standards otherwise a “Red Cross” will be shown in the tab at left hand side. Do not worry about that cross 🙂
Click “Next”.
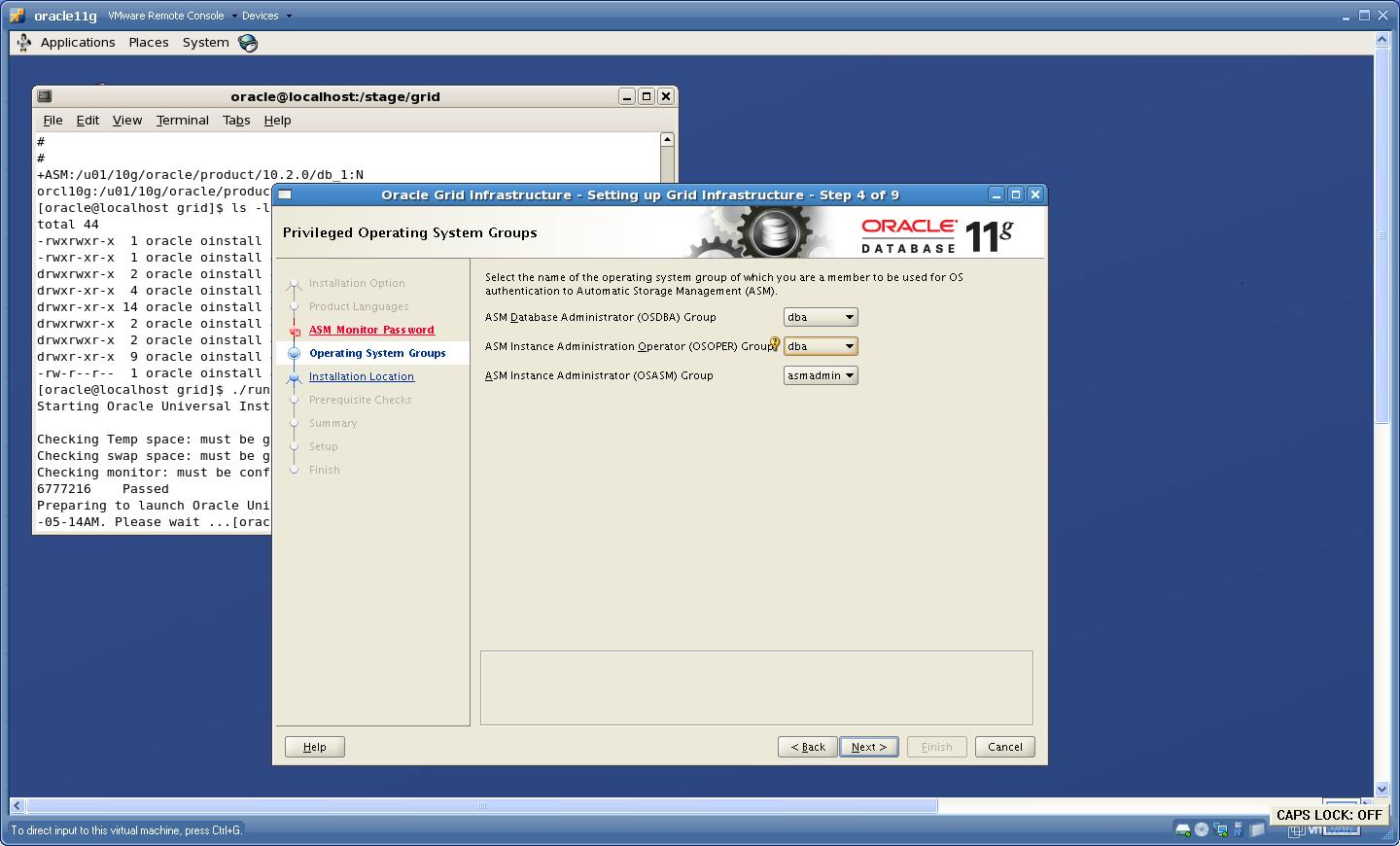
5. Provide the Group details
Click “Next”.
Click “Yes”.
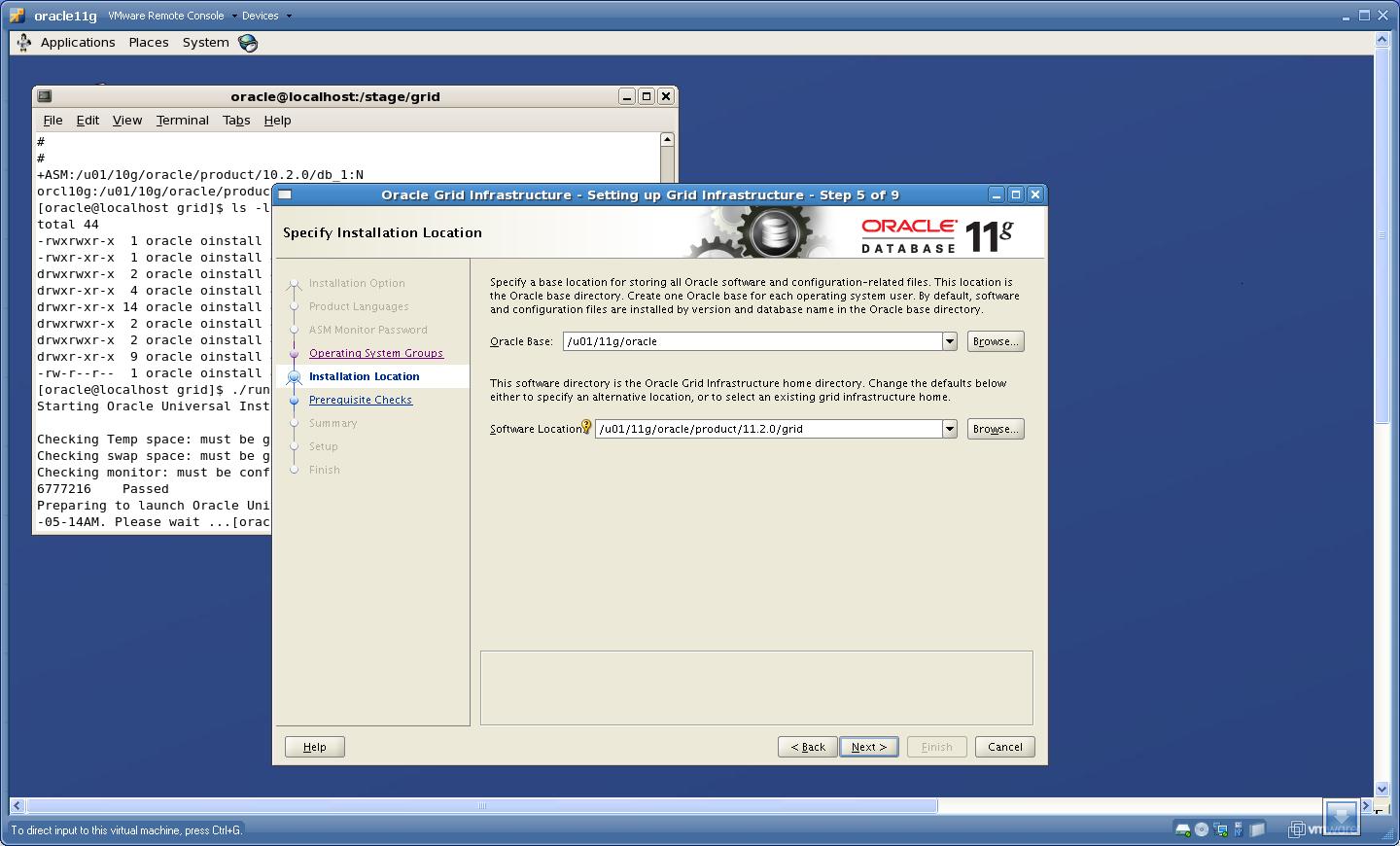
6. Provide the Base and Home location for Grid Infrastructure Home
Click “Next”.
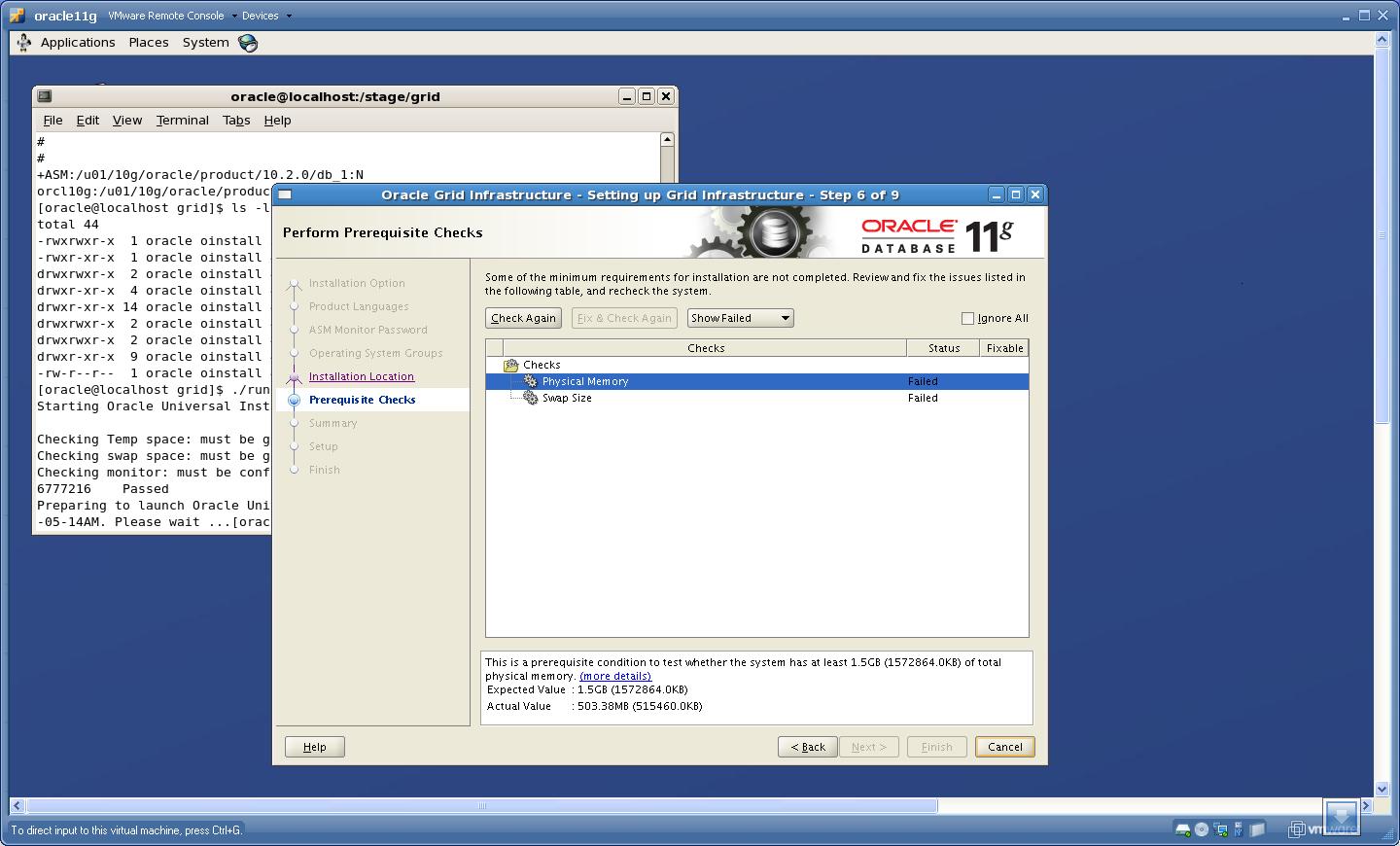
7. It will perform the Prerequisite checks here, For more information on this click Installation Fixup script I have select “Ignore All”
Click “Next”.
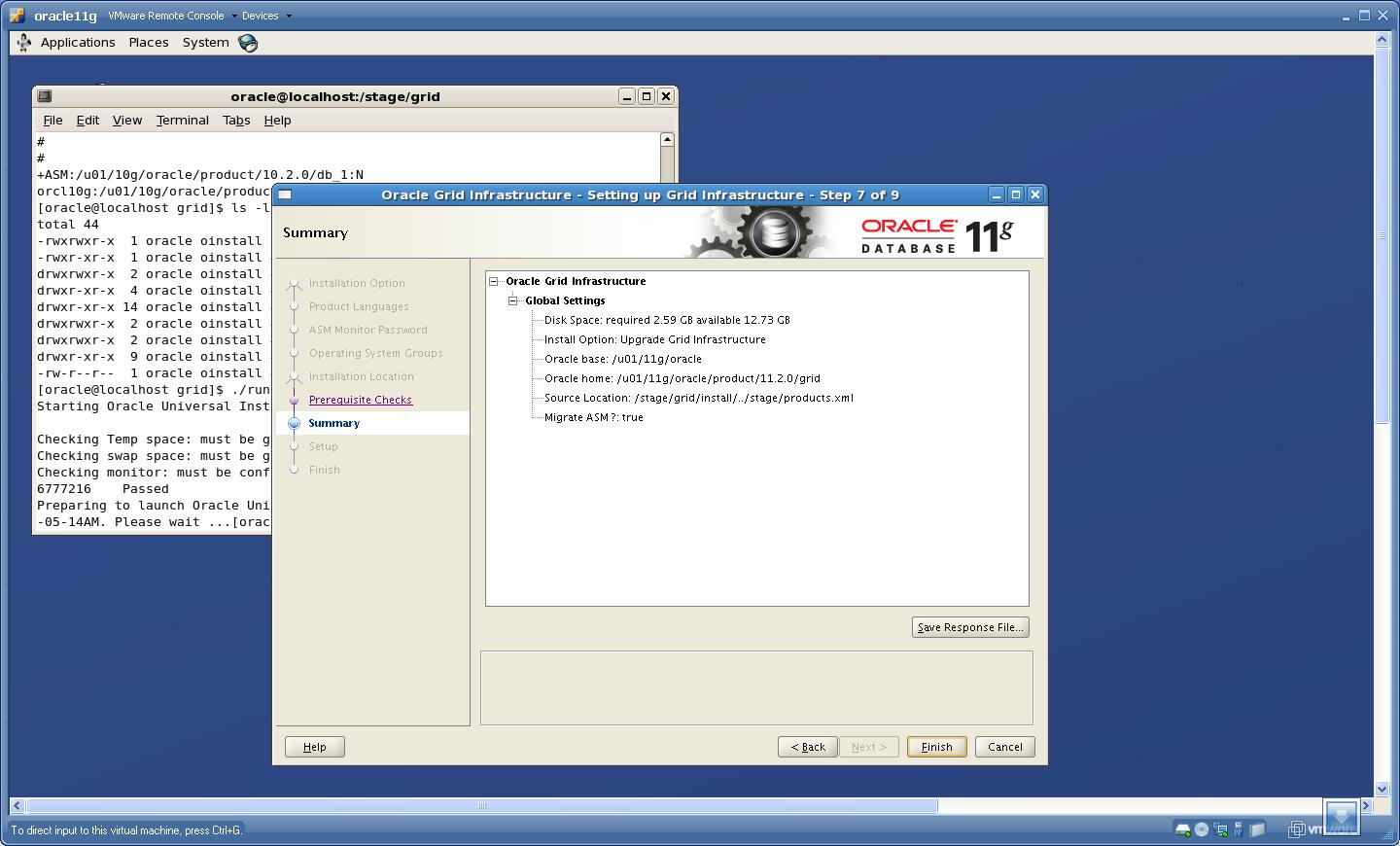
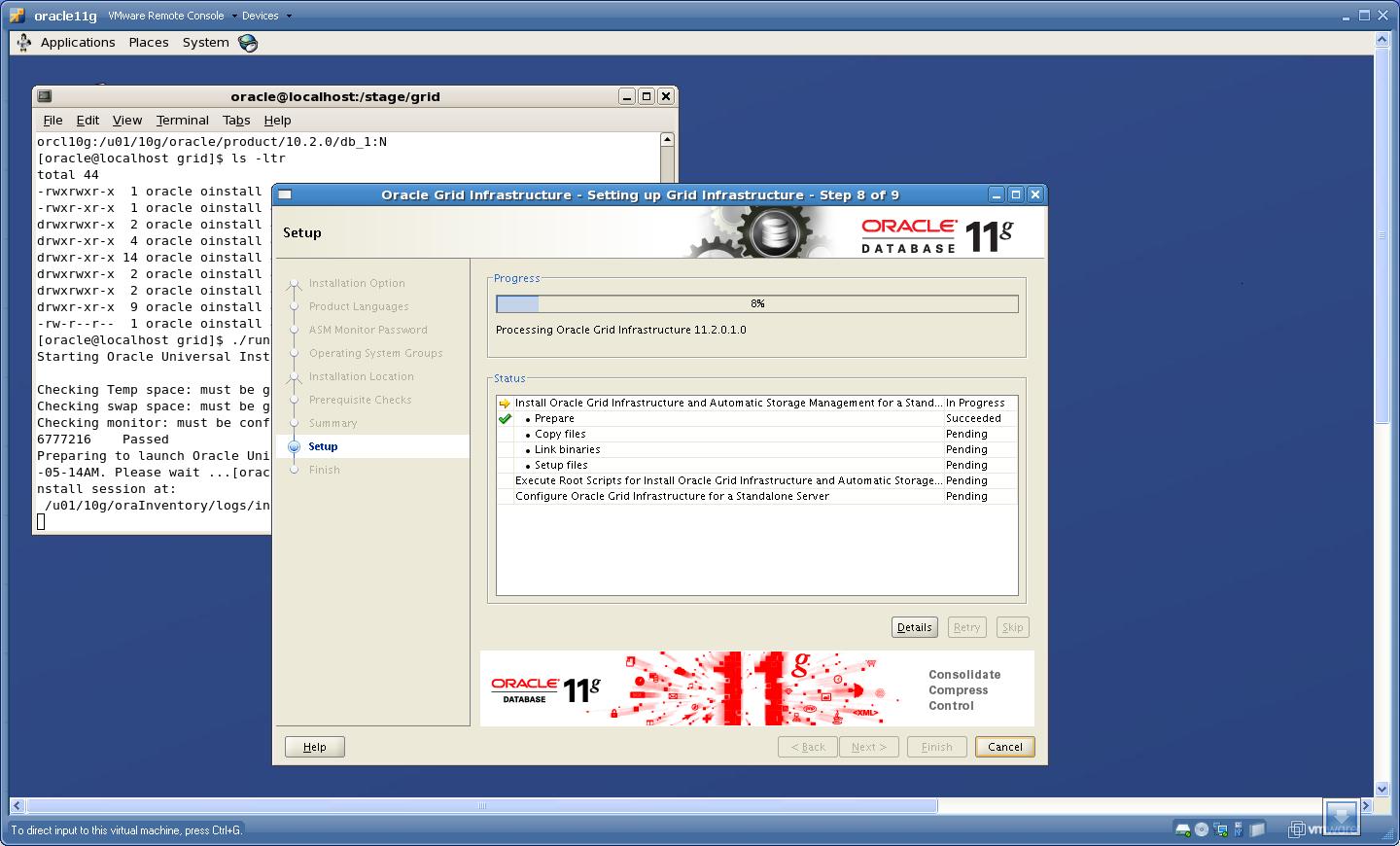
8. Now you will see “Summary” page, make sure that the Installation Option is shown as “Upgrade Grid Infrastructure” and Migrate ASM as “True”.
Click “Finish”.
9. Now the setup for “Grid Infrastructure’ is started
Run the rootupgrade.sh
# ./rootupgrade.sh
[root@localhost ~]# cd /u01/11g/oracle/product/11.2.0/grid/
[root@localhost grid]# pwd
/u01/11g/oracle/product/11.2.0/grid
[root@localhost grid]# ./rootupgrade.sh
Running Oracle 11g root.sh script...
The following environment variables are set as:
ORACLE_OWNER= oracle
ORACLE_HOME= /u01/11g/oracle/product/11.2.0/grid
Enter the full pathname of the local bin directory: [/usr/local/bin]:
The file "dbhome" already exists in /usr/local/bin. Overwrite it? (y/n)
[n]: y
Copying dbhome to /usr/local/bin ...
The file "oraenv" already exists in /usr/local/bin. Overwrite it? (y/n)
[n]: y
Copying oraenv to /usr/local/bin ...
The file "coraenv" already exists in /usr/local/bin. Overwrite it? (y/n)
[n]: y
Copying coraenv to /usr/local/bin ...
Entries will be added to the /etc/oratab file as needed by
Database Configuration Assistant when a database is created
Finished running generic part of root.sh script.
Now product-specific root actions will be performed.
2009-09-05 11:46:25: Checking for super user privileges
2009-09-05 11:46:25: User has super user privileges
2009-09-05 11:46:25: Parsing the host name
Using configuration parameter file: /u01/11g/oracle/product/11.2.0/grid/crs/install/crsconfig_params
Creating trace directory
LOCAL ADD MODE
Creating OCR keys for user 'oracle', privgrp 'oinstall'..
Operation successful.
CSS appears healthy
Stopping CSSD.
Shutting down CSS daemon.
Shutdown request successfully issued.
Shutdown has begun. The daemons should exit soon.
CRS-4664: Node localhost successfully pinned.
Adding daemon to inittab
CRS-4123: Oracle High Availability Services has been started.
ohasd is starting
localhost 2009/09/05 11:49:02 /u01/11g/oracle/product/11.2.0/grid/cdata/localhost/backup_20090905_114902.olr
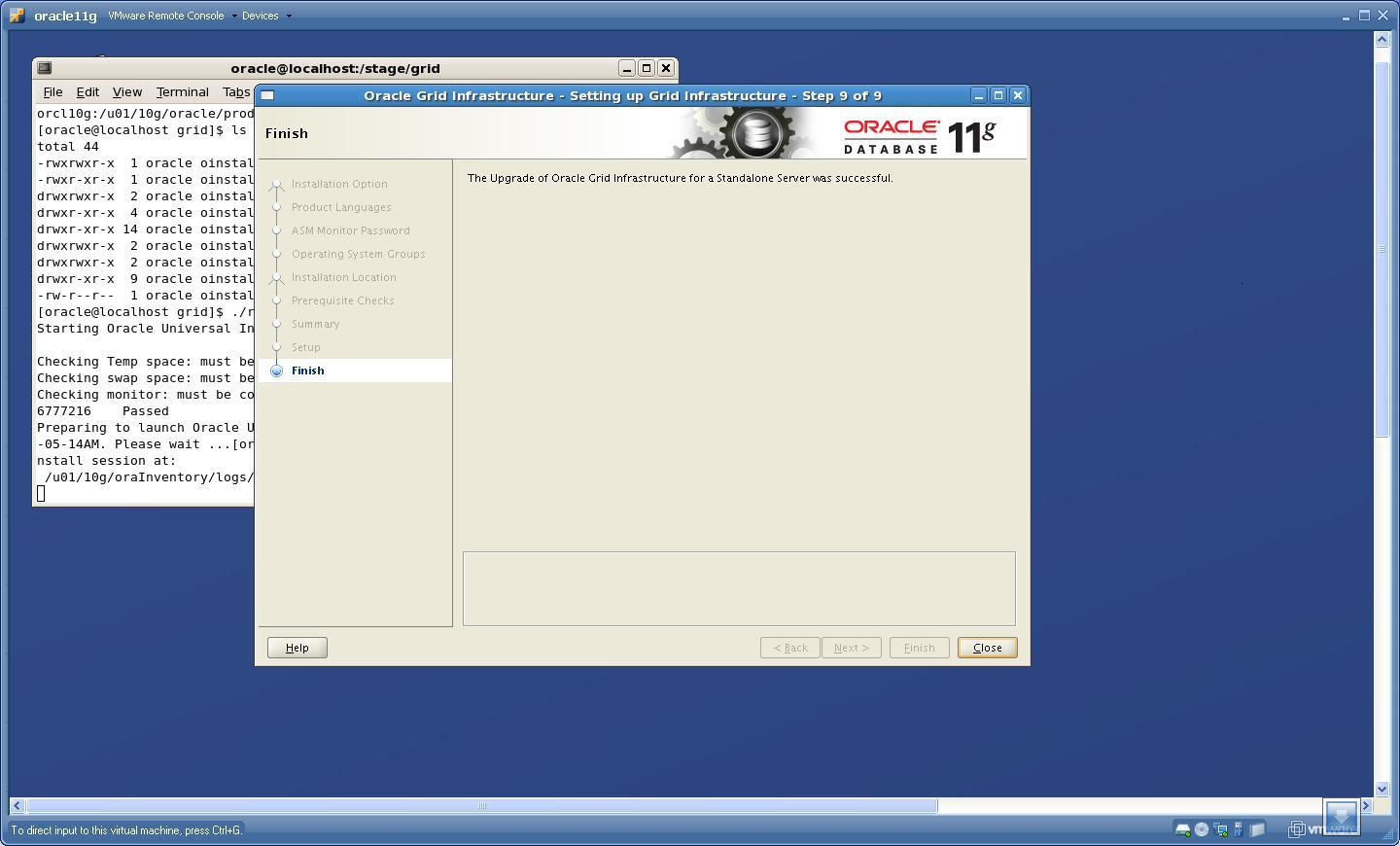
Successfully configured Oracle Grid Infrastructure for a Standalone Server
Updating inventory properties for clusterware
Starting Oracle Universal Installer...
Checking swap space: must be greater than 500 MB. Actual 885 MB Passed
The inventory pointer is located at /etc/oraInst.loc
The inventory is located at /u01/10g/oraInventory
'UpdateNodeList' was successful.
[root@localhost grid]#
10. After the upgrade I have checked /etc/oratab file and found the entry of ASM pointing to new home i.e now ASM is a part of “Grid Infrastructure”
“+ASM:/u01/11g/oracle/product/11.2.0/grid:N”
Upgrade Database Instance: ===================
NOTE: DO NOT SHUTDOWN DATABASE BEFORE RUNNING DBUA.
STEP 1: Install The Software:
To download Oracle Database 11gR2 software click Here . Execute runInstaller to install “SOFTWARE ONLY” option, you can follow this link to install the software. Make sure that you select “software only” option as shown below rest of the steps are same as described in above link.
STEP 2: Run Pre-Upgrade Information tool
I have installed the software under “/u01/11g/oracle/product/11.2.0/dbhome_1” location. Once the software is installed, then go to location $ORACLE_HOME/rdbms/admin and copy utlu112i.sql script to /tmp directory. Now login to 10g database “/ as sysdba” and startup the 10g database, then:
Following is the output of this script from my database:
Oracle Database 11.2 Pre-Upgrade Information Tool 09-04-2009 01:54:32
.
**********************************************************************
Database:
**********************************************************************
--> name: ORCL10G
--> version: 10.2.0.3.0
--> compatible: 10.2.0.3.0
--> blocksize: 8192
--> platform: Linux IA (32-bit)
--> timezone file: V3
.
**********************************************************************
Tablespaces: [make adjustments in the current environment]
**********************************************************************
--> SYSTEM tablespace is adequate for the upgrade.
.... minimum required size: 724 MB
.... AUTOEXTEND additional space required: 244 MB
--> UNDOTBS1 tablespace is adequate for the upgrade.
.... minimum required size: 464 MB
.... AUTOEXTEND additional space required: 439 MB
--> SYSAUX tablespace is adequate for the upgrade.
.... minimum required size: 447 MB
.... AUTOEXTEND additional space required: 207 MB
--> TEMP tablespace is adequate for the upgrade.
.... minimum required size: 61 MB
.... AUTOEXTEND additional space required: 41 MB
.
**********************************************************************
Flashback: OFF
**********************************************************************
**********************************************************************
Update Parameters: [Update Oracle Database 11.2 init.ora or spfile]
**********************************************************************
WARNING: --> "sga_target" needs to be increased to at least 336 MB
WARNING: --> "java_pool_size" needs to be increased to at least 64 MB
WARNING: --> "pga_aggregate_target" needs to be increased to at least 24 MB
.
**********************************************************************
Renamed Parameters: [Update Oracle Database 11.2 init.ora or spfile]
**********************************************************************
-- No renamed parameters found. No changes are required.
.
**********************************************************************
Obsolete/Deprecated Parameters: [Update Oracle Database 11.2 init.ora or spfile]
**********************************************************************
--> background_dump_dest 11.1 DEPRECATED replaced by
"diagnostic_dest"
--> user_dump_dest 11.1 DEPRECATED replaced by
"diagnostic_dest"
--> core_dump_dest 11.1 DEPRECATED replaced by
"diagnostic_dest"
.
**********************************************************************
Components: [The following database components will be upgraded or installed]
**********************************************************************
--> Oracle Catalog Views [upgrade] VALID
--> Oracle Packages and Types [upgrade] VALID
--> JServer JAVA Virtual Machine [upgrade] VALID
--> Oracle XDK for Java [upgrade] VALID
--> Oracle Workspace Manager [upgrade] VALID
--> OLAP Analytic Workspace [upgrade] VALID
--> OLAP Catalog [upgrade] VALID
--> EM Repository [upgrade] VALID
--> Oracle Text [upgrade] VALID
--> Oracle XML Database [upgrade] VALID
--> Oracle Java Packages [upgrade] VALID
--> Oracle interMedia [upgrade] VALID
--> Spatial [upgrade] VALID
--> Data Mining [upgrade] VALID
--> Expression Filter [upgrade] VALID
--> Rule Manager [upgrade] VALID
--> Oracle OLAP API [upgrade] VALID
.
**********************************************************************
Miscellaneous Warnings
**********************************************************************
WARNING: --> Database is using a timezone file older than version 11.
.... After the release migration, it is recommended that DBMS_DST package
.... be used to upgrade the 10.2.0.3.0 database timezone version
.... to the latest version which comes with the new release.
WARNING: --> Database contains schemas with stale optimizer statistics.
.... Refer to the Upgrade Guide for instructions to update
.... schema statistics prior to upgrading the database.
.... Component Schemas with stale statistics:
.... SYS
.... XDB
WARNING: --> Database contains schemas with objects dependent on network
packages.
.... Refer to the Upgrade Guide for instructions to configure Network ACLs.
WARNING: --> EM Database Control Repository exists in the database.
.... Direct downgrade of EM Database Control is not supported. Refer to the
.... Upgrade Guide for instructions to save the EM data prior to upgrade.
WARNING:--> recycle bin in use.
.... Your recycle bin turned on.
.... It is REQUIRED
.... that the recycle bin is empty prior to upgrading
.... your database.
.... The command: PURGE DBA_RECYCLEBIN
.... must be executed immediately prior to executing your upgrade.
PL/SQL procedure successfully completed.
SQL> spool off
Adjust the warnings shown by Pre-Upgrade Information tool.
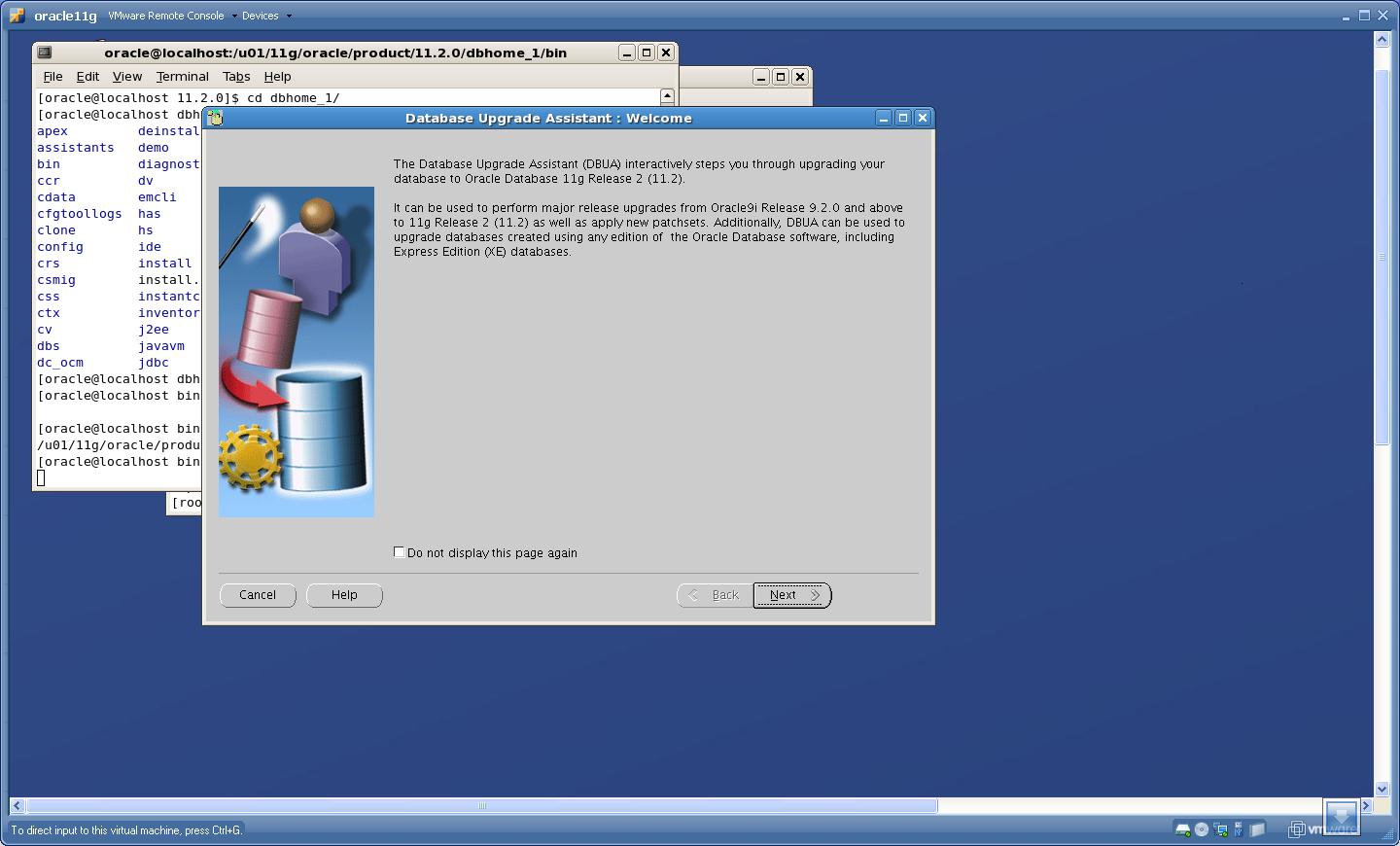
STEP 3 :Upgrade using DBUA
Execute the DBUA from 11gR2 software home as
$ cd $ORACLE_HOME/bin
$./dbua
1.
Click “Next”
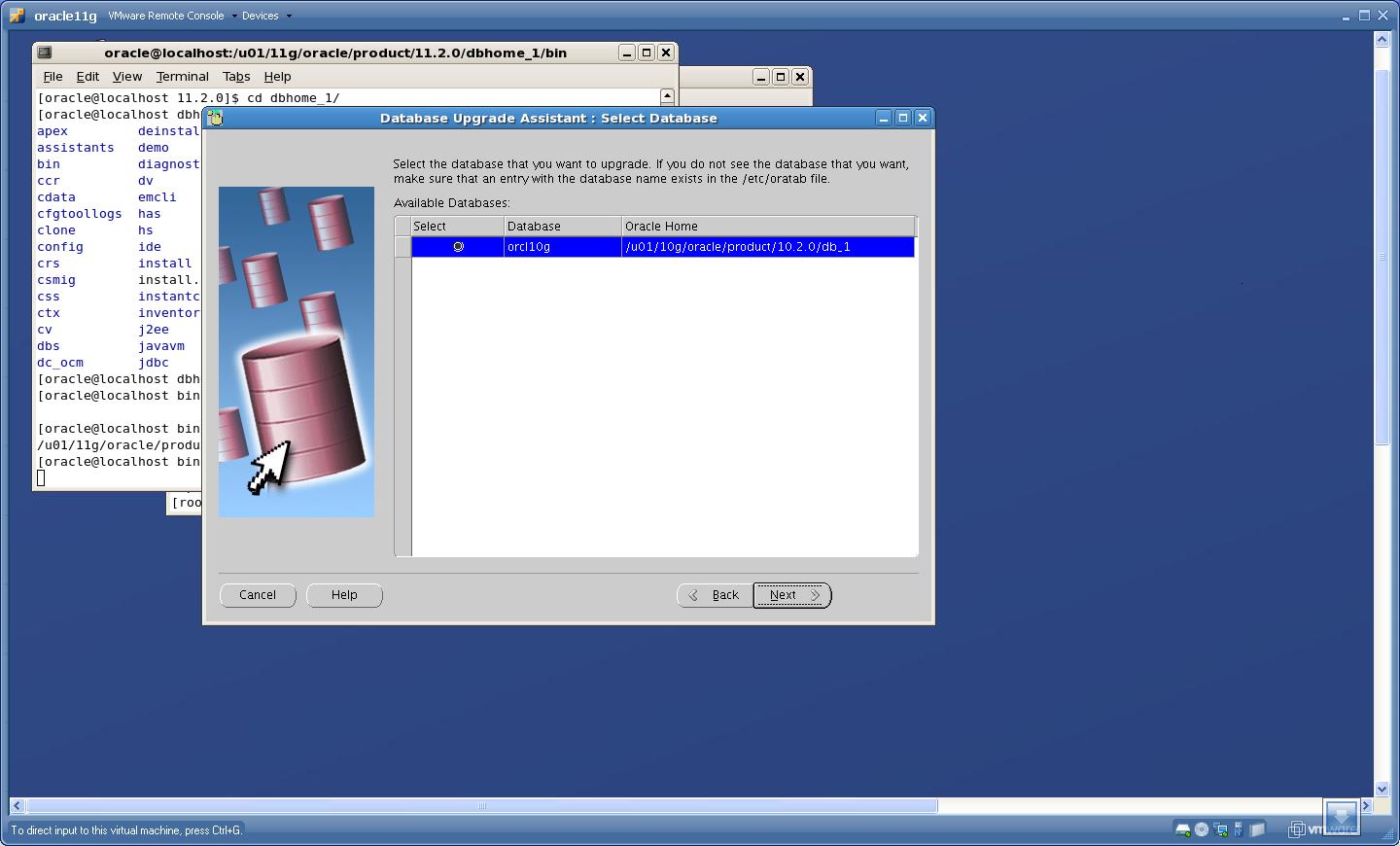
2. Select the database that you want to upgrade
Click “Next”
3. Here DBUA will show warnings that were not solved after running Pre-Upgrade Information tool
Click “Yes”
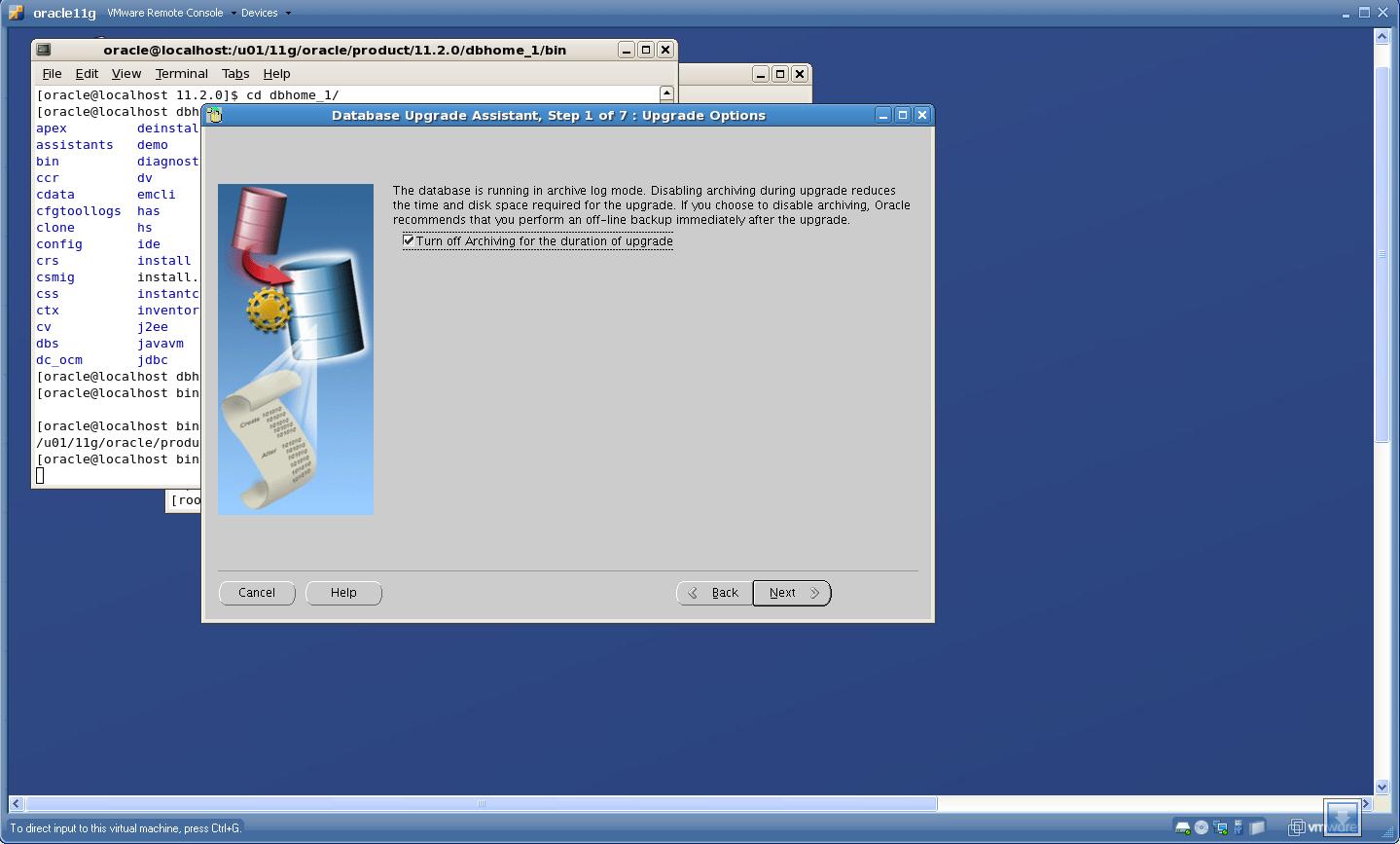
4. Turn OFF archiving while upgrading
Click “Next”
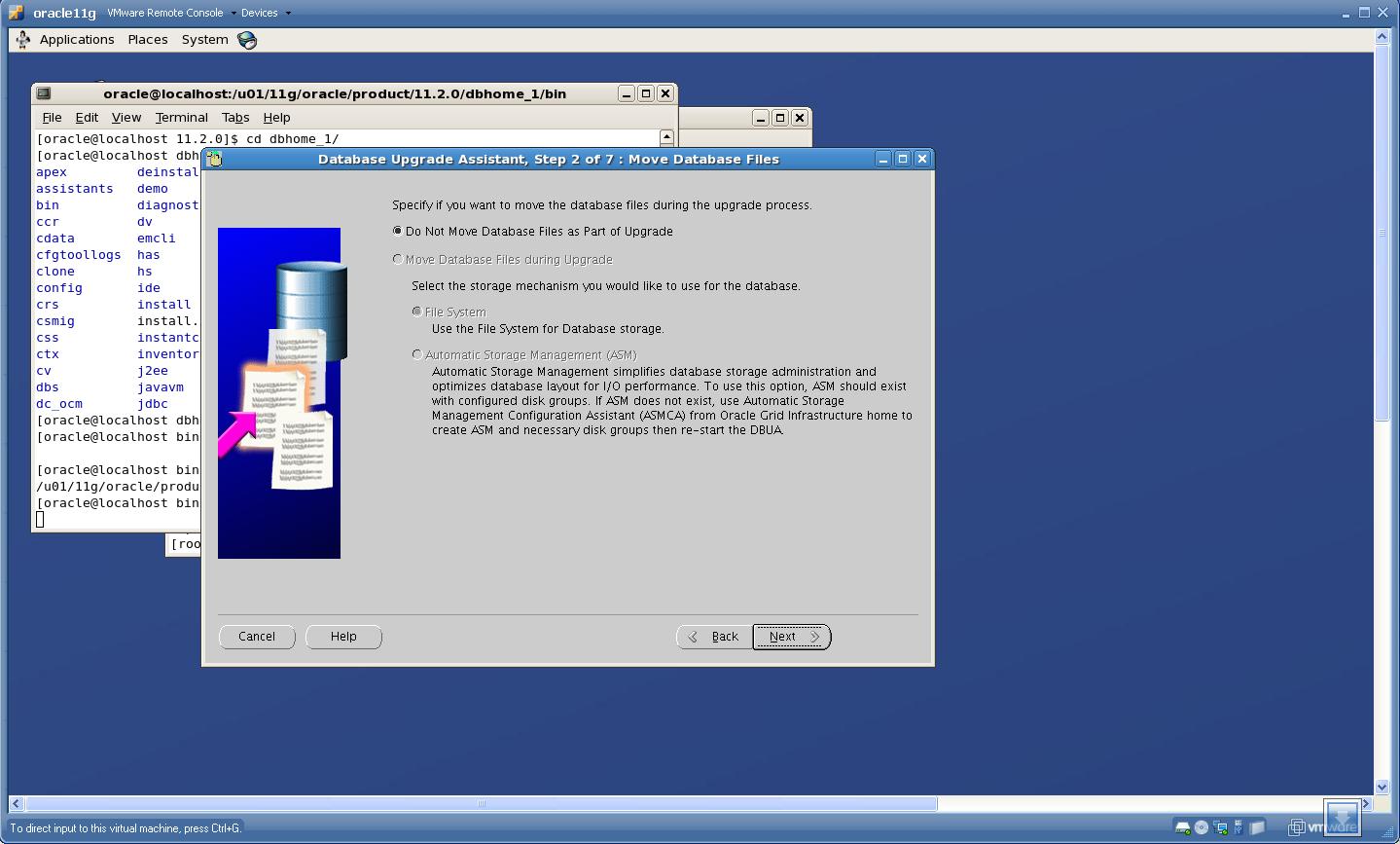
5. Check whether you want to move the datafiles while upgrade, though the “move datafile” check-box was not highlighted when I upgraded
Click “Next”.
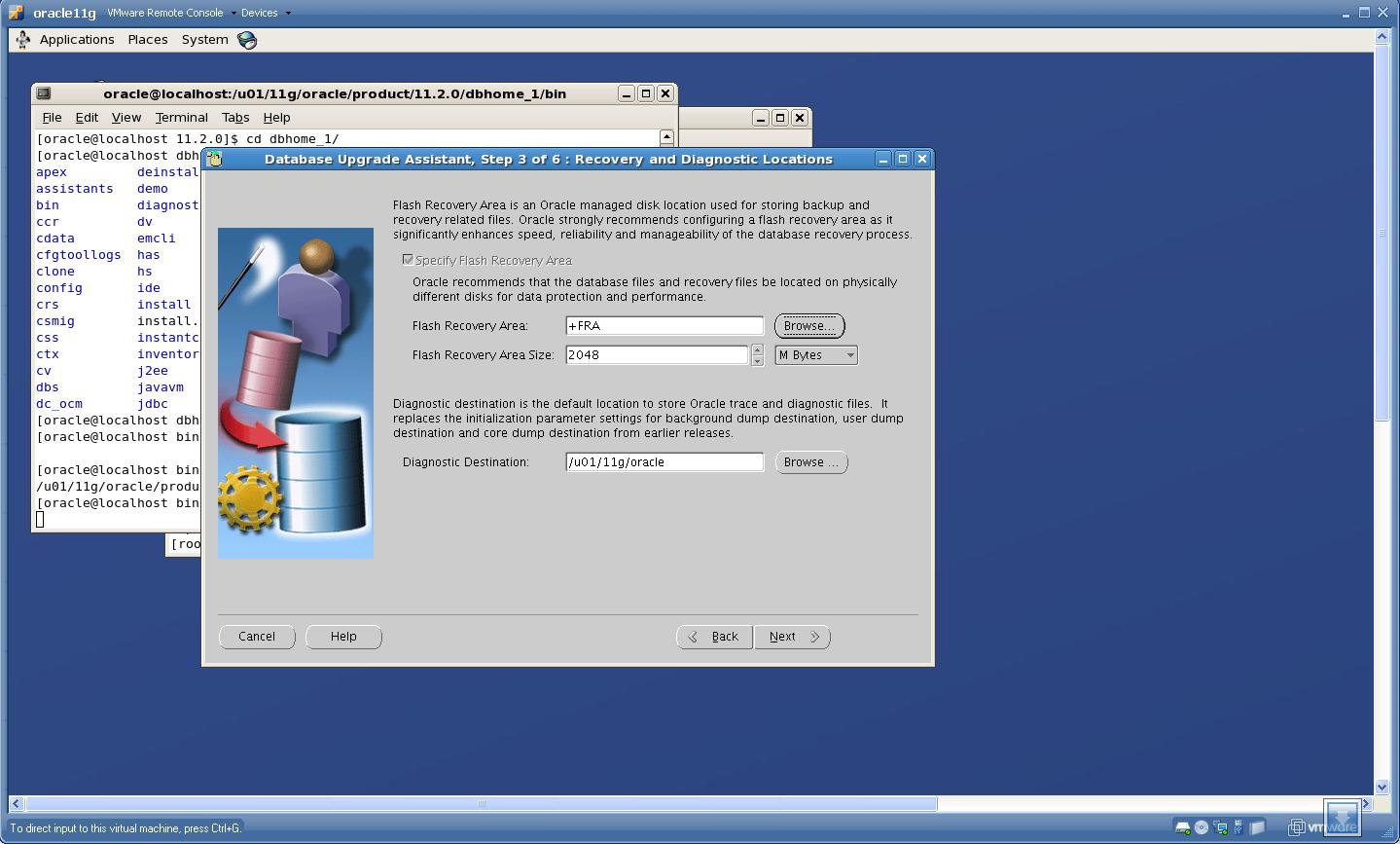
6. Specify “FRA” and “Diagnostic Destination”
Click “Next”.
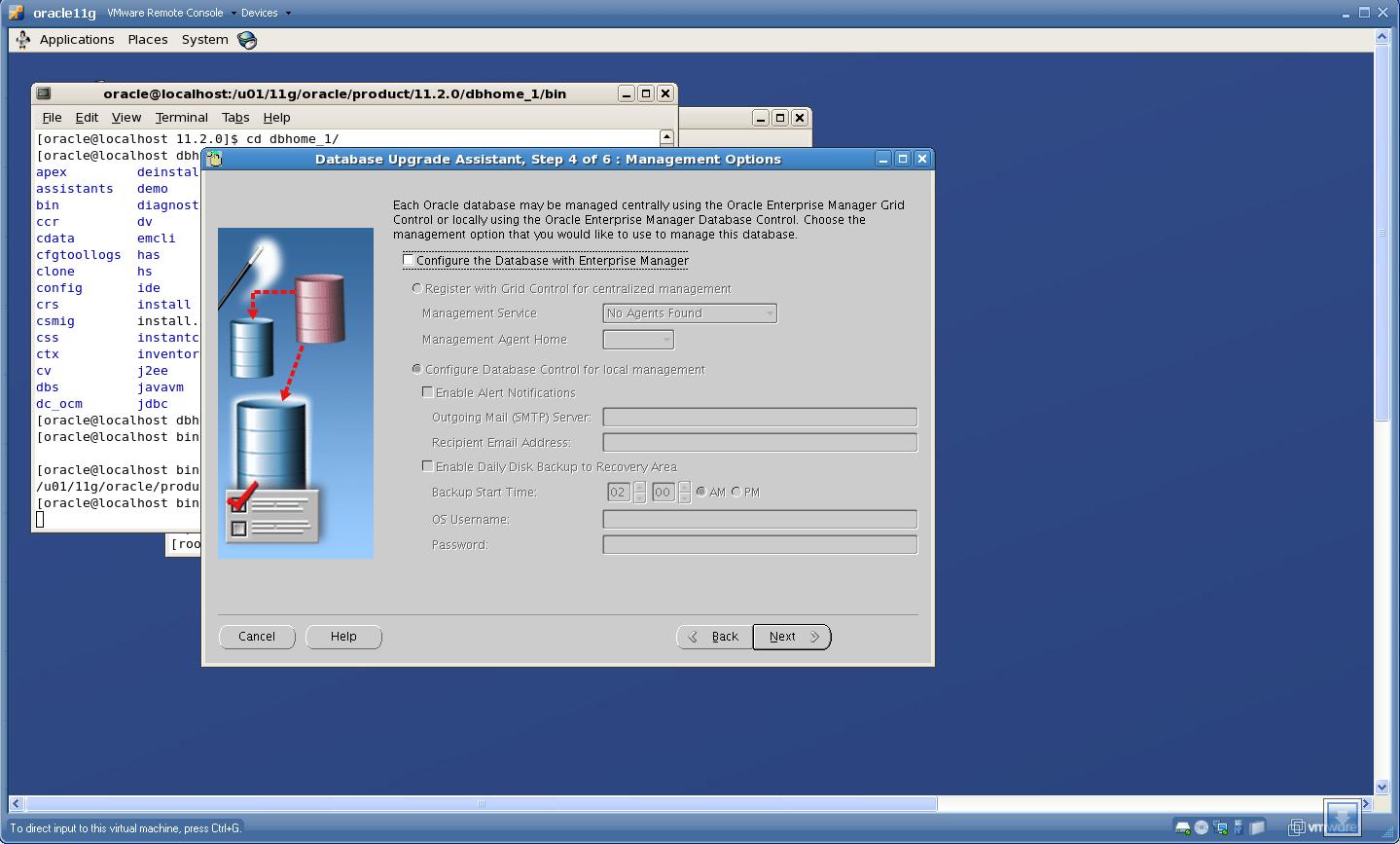
7. Check configuration for EM
Click “Next”.
8. Check “Summary” page
Click “Finish”
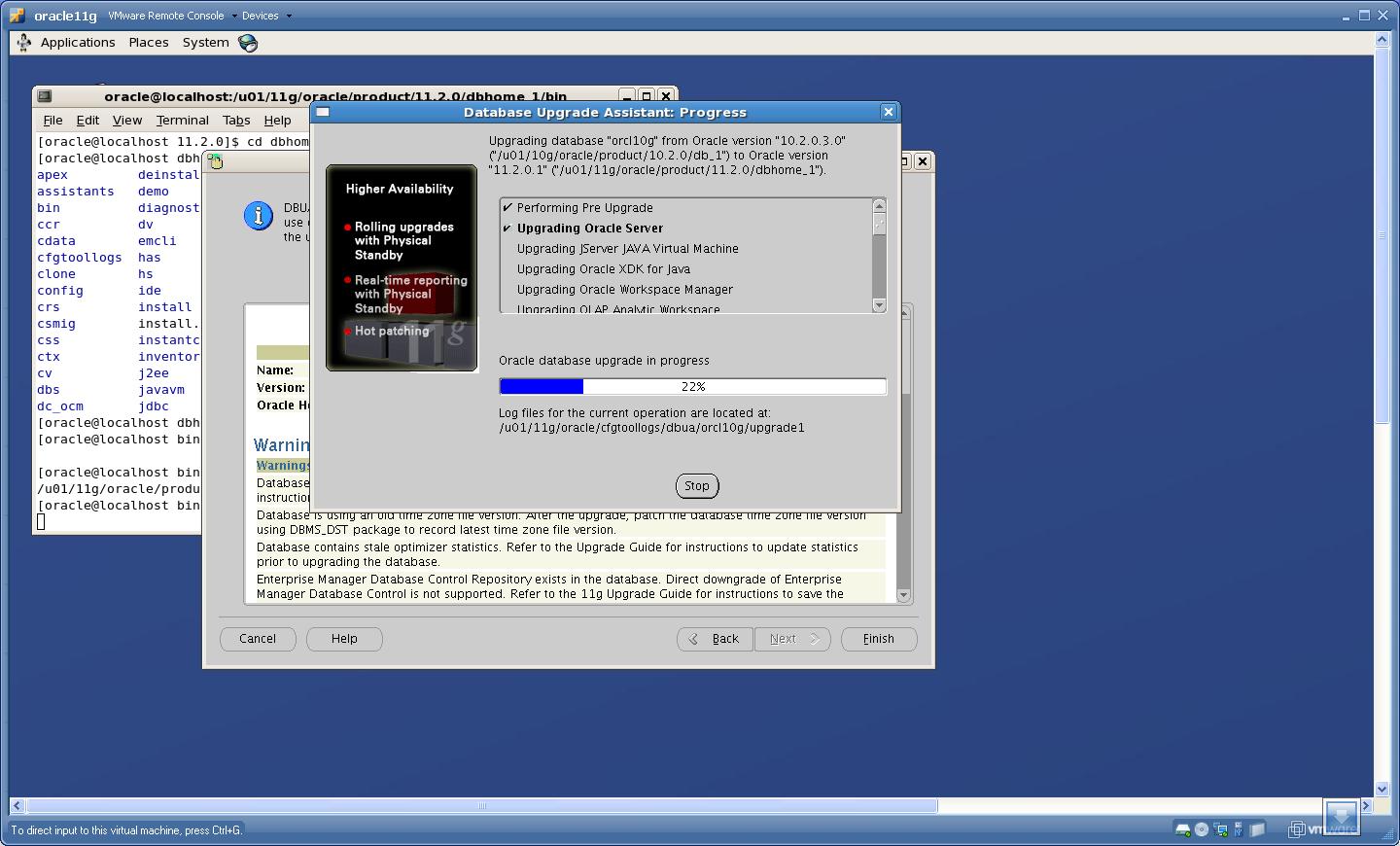
Upgrade Process is started
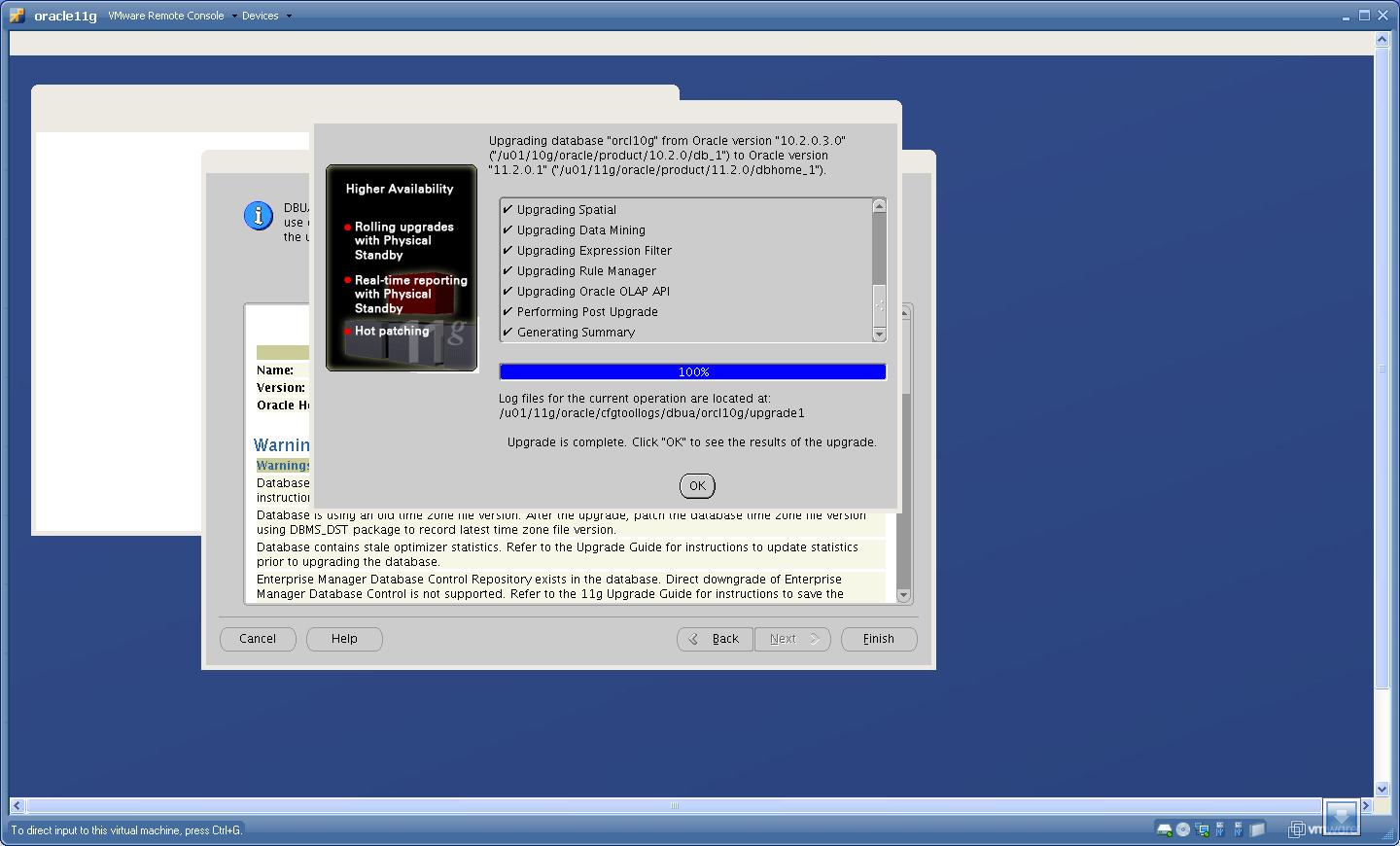
Check the Results
Congratulations!!!!!!!!!! Upgrade is Successful !!!!!!!!!!!!!!!
Now you are ready to use Most Powerful Database!! 🙂
While setting up ocfs2 for OCR and Voting disk storage with following commad:
# ocfs2console
After clicking on ==>cluster ==> configure nodes, I got a pop-up saying:
<span style="font-size: small;"><span style="font-family: arial,helvetica,sans-serif;">"Could not start cluster stack. This must be resolved before any OCFS2 filesystem can be mounted."</span></span>
Soon I realized that the thing which takes few minutes to get installed, is going to give me a tough time.
/var/log/messages shows following details:
<span style="font-size: small;"><span style="font-family: arial,helvetica,sans-serif;">Aug 17 14:53:40 rac1 modprobe: FATAL: Module configfs not found.
Aug 17 14:55:23 rac1 modprobe: FATAL: Module configfs not found.
Aug 17 14:56:56 rac1 modprobe: FATAL: Module configfs not found.
</span></span>
This prevents the configuration of OCFS2’s cluster stack, but it is mandatory to have OCFS2 cluster stack “O2CB” running, before
we can start anything with OCFS2 filesystem.
The stack includes the following services:
<span style="font-size: small;"><span style="font-family: arial,helvetica,sans-serif;"> * NM: Node Manager that keep track of all the nodes in the cluster.conf
* HB: Heart beat service that issues up/down notifications when nodes join or leave the cluster
* TCP: Handles communication between the nodes
* DLM: Distributed lock manager that keeps track of all locks, its owners and status
* CONFIGFS: User space driven configuration file system mounted at /config
* DLMFS: User space interface to the kernel space DLM
</span></span>
“Error : modprobe: FATAL: Module configfs not found” can occur because of following reasons:
1. SELINUX is enabled.
2. Mismatch between the Kernel and OCFS2 module.
1. To check for selinux:
# sestatus
Or
# vi /etc/sysconfig/selinux
Make sure that selinux is DISABLED here.
2. To check for Mismatch:
# uname -a (It will give the exact kernel version of the OS)
2.6.9-42.ELsmp
# rpm -qa |grep ocfs2 (It will tell us the ocfs2 package currently installed)
ocfs2-2.6.9-89.EL
Here it can be seen that ocfs2 is for kernel version 89 not for kernel version 42.
Few days back , Martin had posted a series of post on a issue where GATHER_STATS_JOB was failing silently for a large object. If you have missed it, you can check following links
This post is based on some of the discussions on the thread. Please note that this is not intended to discuss bugs (if any) associated with the job
Gather_stats_job was introduced with Oracle 10g to gather statistics for database objects which has stale statistics (10% of data has changed, you can query dba_tab_modifications) or the tables for which the statistics has not been gathered (new tables created/truncated). This job runs during the maintenance window i.e every night from 10 P.M. to 6 A.M. and all day on weekends. This schedule can be though changed and process is documented in Metalink aka My Oracle Support Note 579007.1 –
This feature brought relief to lot of DBA’s as they did not have to write shell scripts to gather stats and could rely on this job to do the work. But slowly people realized that it does not fit in their environment and slowly recommendation turned from “Enabled ” to “Disabled “
Issues/Misconceptions
1) Should I schedule job run for every night?
As documented this job gathers stats on the tables which have got 10% of data changes since last run. So this will not touch the tables for which the data changes are less then 10%. Also due to rolling invalidation feature , sql cursors will not be immediately invalidated (Refer to oracle forums discussion and Fairlie Rego’s post)
If you are still not happy , you can change the maintenance window timings to suit the schedule (say on weekends)
In 11g, there is no GATHER_STATS_JOB. It has been now incorporated into DBMS_AUTO_TASK_ADMIN job along with Automatic segment advisor and Automatic tuning advisor. All these 3 run in all maintenance windows. New maintenance windows introduced with 11g are
You can check the name and state of this job using following query
SQL> SELECT client_name, status FROM dba_autotask_operation;
CLIENT_NAME STATUS
---------------------------------------------------------------- --------
auto optimizer stats collection ENABLED
auto space advisor ENABLED
sql tuning advisor ENABLED
Window – Description
MONDAY_WINDOW – Starts at 10 p.m. on Monday and ends at 2 a.m.
TUESDAY_WINDOW – Starts at 10 p.m. on Tuesday and ends at 2 a.m.
WEDNESDAY_WINDOW -Starts at 10 p.m. on Wednesday and ends at 2 a.m.
THURSDAY_WINDOW – Starts at 10 p.m. on Thursday and ends at 2 a.m.
FRIDAY_WINDOW -Starts at 10 p.m. on Friday and ends at 2 a.m.
SATURDAY_WINDOW – Starts at 6 a.m. on Saturday and is 20 hours long.
SUNDAY_WINDOW -Starts at 6 a.m. on Sunday and is 20 hours long.
2) I do not want gather_stats_job to gather stats on some of my tables.
This requirement can arise due to following points
a)There are tables for which you have set the stats manually
b) There are queries for which you know your old stats will work fine
c) Tables are big and gather_stats_job is silently failing ( Again refer to Martin’s Post)
d) Tables for which histograms cannot not be gathered or vice versa
e) Tables for which you would like to estimate fixed percent of blocks
For all these situations. you can use DBMS_STATS.LOCK_TABLE_STATS and gather stats manually with force =>true to override locked statistics. For big partitioned tables you can use COPY_TABLE_STATS and APPROX_GLOBAL AND PARTITION feature.
Oracle 11g also has enhancement to gathering stats on partitioned tables where in you can gather INCREMENTAL stats for partitions and oracle will automatically update global stats for table.This approach has advantage as we don’t scan table twice and reduces the time to gather stats drastically. You need to use DBMS_STATS.set_table_prefs procedure to set Incremental stats gathering to true.
Note that first time, stats gathering will take more time as oracle will create object called synposes for each paritition. Subsequent runs of gather_stats_job will be faster. Refer to Optimizer group post for more info on copy_table_stats and 11g incremental stats feature. ( Due to bug copy_table_stats does not alter low/high value. Details can be found here )
To fix histogram issue, DBMS_STATS.SET_PARAM can be used to modify the default attributes e.g By default, GATHER_STATS_JOB will gather histograms, which can be confirmed by running below query
select dbms_stats.get_param('method_opt') method_opt from dual;
METHOD_OPT
--------------------------------------------------------------------
FOR ALL COLUMNS SIZE AUTO
To disable histogram capture, use
exec dbms_stats.set_param('method_opt', 'FOR ALL COLUMNS SIZE 1');
In case you wish to capture histograms for some of the tables, then you can use
exec dbms_stats.set_param('method_opt', 'FOR ALL COLUMNS SIZE REPEAT')
i.e Collects histograms only on the columns that already have histograms
Starting Oracle 11g database you can use DBMS_STATS.SET_*_PREFS to take care of point (d) and (e) i.e you can change the default gather options for particular table. Details can be found here
This is not exhaustive list and I hope that this will grow so that we can have Recommendation for GATHER_STATS_JOB status to be set to “SCHEDULED” 🙂
This post discusses issue faced by me while working on Materialized view (mview) creation at new site(database). Starting Oracle 10g, how atomic_refresh works with complete refresh has undergone a change.
Atomic_refresh parameter is to allow either all of the tasks of a transaction are performed or none of them (Atomicity). If set to TRUE, then all refreshes are done in one transaction. If set to FALSE, then the refresh of each specified materialized view is done in a separate transaction.
In case of 9i if a single mview was refreshed , it used to be truncated and then refreshed (which actually was not atomic). In case of multiple mviews being refreshed (part of refresh group), rows were deleted and then the insert was done.
As part of change in 10g, if atomic_refresh is set to true (By defualt) , rows will be deleted one by one and then insert will take place for both single mview or multiple mviews in refresh group. So if you need to truncate the mview before then set atomic_refresh =>false (default True) while doing a complete refresh.
Due to this change you will find many issues like high redo generation and longer time for complete refresh of mviews using dbms_mview.refresh as now in 10g it will go for deleting the rows and not truncate.
In our case a DBA issued a complete refresh for mview with size of 195Gb (having around 8 indexes ). After 16 hours of running, refresh job was still deleting the rows and had not started inserting the rows. At this moment we decided to kill the refresh session. As this session had generated a lot of undo, smon kicked in to recover the transaction.
On checking the V$FAST_START_TRANSACTION , it reported that it will take around 2 months to perform the rollback.
This post discusses issue faced by me while working on Materialized view (mview) creation at new site(database). Starting Oracle 10g, how atomic_refresh works with complete refresh has undergone a change.
Atomic_refresh parameter is to allow either all of the tasks of a transaction are performed or none of them (Atomicity). If set to TRUE, then all refreshes are done in one transaction. If set to FALSE, then the refresh of each specified materialized view is done in a separate transaction.If set to FALSE, Oracle can optimize refresh by using parallel DML and truncate DDL on a materialized views.
In case of 9i (atomic_refresh =>true), if a single mview was refreshed , it used to be truncated and then refreshed (which actually was not atomic). In case of multiple mviews being refreshed (part of refresh group), rows were deleted and then the insert was done.
As part of change in 10g, if atomic_refresh is set to true (By defualt) , rows will be deleted one by one and then insert will take place for both single mview or multiple mviews in refresh group. So if you need to truncate the mview before then set atomic_refresh =>false (default True) while doing a complete refresh.
Due to this change you will find many issues like high redo generation and longer time for complete refresh of mviews using dbms_mview.refresh as now in 10g it will go for deleting the rows and not truncate.
In our case a DBA issued a complete refresh without setting atomic_refresh to false for mview with size of 195Gb (plus 8 indexes ). After 16 hours of running, refresh job was still deleting the rows and had not started inserting the rows. At this moment we decided to kill the refresh session. As this session had generated a lot of undo, smon kicked in to recover the transaction.
On checking the V$FAST_START_TRANSACTION , it reported that it will take around 2 months to perform the rollback.
fast_start_parallel_rollback was set to value of low. We see 50 processes were spawned and only one of the parallel server was doing the recovery indicating that the parallel servers might be interfering with each other. Metalink Note 144332.1 (- Parallel Rollback may hang database, Parallel query servers get 100% cpu) discusses this behavior. Now I decided to use the serial recovery by changing fast_start_parallel_rollback to false. But to do this , we had to disable the SMON to do transaction recovery using event 10513 at level 2.
SQL> oradebug setorapid 22
Unix process pid: 2728024, image: oracle@ods1 (SMON)
SQL> oradebug Event 10513 trace name context forever, level 2
Statement processed.
SQL> select 'kill -9 '||spid||' ' from V$process where pid in (select pid from V$FAST_START_SERVERS);
'KILL-9'||SPID||''
---------------------
kill -9 3014818
kill -9 3010772
kill -9 2916434
kill -9 2887716
kill -9 2678958
kill -9 2511030
kill -9 2224314
kill -9 2142210
kill -9 2822282
kill -9 2625696
kill -9 2506808
kill -9 2486520
kill -9 2314492
kill -9 2310186
kill -9 2752764
kill -9 2445478
kill -9 2326692
kill -9 2457716
kill -9 2654394
kill -9 2621630
kill -9 2580502
kill -9 2633960
kill -9 2412686
alter system set fast_start_parallel_rollback=false;
SQL> select usn, state, undoblockstotal "Total", undoblocksdone "Done", undoblockstotal-undoblocksdone "ToDo", decode(cputime,0,'unknown',sysdate+(((undoblockstotal-undoblocksdone) / (undoblocksdone / cputime)) / 86400)) "Estimated time to complete"
2 from v$fast_start_transactions;
USN STATE Total Done ToDo Estimated time to co
---------- ---------------- ---------- ---------- ---------- --------------------
51 RECOVERING 3513444 6002 3507442 06-JUL-2009 17:58:03
SQL> select * from V$FAST_START_SERVERS;
no rows selected
Using serial recovery reduced estimated time to 5 hours.
To summarize, if you are still in process of upgrading 9i database to 10g database, then revisit your shell scripts and oracle dbms_jobs used for performing complete refresh of mviews and set atomic_refresh =>false explicitly to truncate the mview before refresh.
There are situations when we see “temporary segments” in permanent tablespaces hanging around and not getting cleaned up.
These temporary segments in permanent tablespace can be created by DDL operations like CTAS and “alter index..rebuild” because
the new object is created as a temporary segment in the target tablespace and when the DDL action finishes it will be changed to permanent type.
These temporary segments take actual disk space when SMON fails to perform its assigned job to cleanup stray temporary segments.
Following query finds out these segments:
Here we can see that tablespace KMRPT_DATA, SPCT_INDEX and SPCT_DATA have large temporary segments.
To know if any DDL is active which can create temporary segments we can use the following:
SQL> conn / as sysdba
SQL> select owner FROM dba_segments WHERE segment_name='345.87';
SQL> select pid from v$process where username='owner from above query';
SQL> alter session set tracefile_identifier='TEMPORARY_SEGMENTS';
SQL> oradebug setorapid <pid obtained>
SQL> oradebug dump errorstack 3
SQL > oradebug tracefile_name
It will give you the tracefile name, open that file and check for the “current sql”
If it is a DDL like CTAS or index rebuild, then wait for the operation to complete. If there is no pid
returned then these segments are “stray segements” and needs to cleaned up manually.
There are two ways to force the drop of temporary segments:
1. Using event DROP_SEGMENTS
2. Corrupting the segments and dropping these corrupted segments.
1. Using DROP_segments:
Find out the tablespace number (ts#) which contains temporary segments:
SQL> select ts# from sys.ts$ where name = 'tablespace name';
Suppose it comes out to be 10, use the following command to cleanup temporary segments:
SQL> alter session set events 'immediate trace name DROP_SEGMENTS level 11';
level is ts#+1 i.e 10+1=11 in this case.
2. Corrupting temporary segments for drop:
For this following procedures are used:
– DBMS_SPACE_ADMIN.TABLESPACE_VERIFY
– DBMS_SPACE_ADMIN.SEGMENT_CORRUPT
– DBMS_SPACE_ADMIN.SEGMENT_DROP_CORRUPT
— Verify the tablespace that contains temporary segments (In this case it is KMRPT_DATA)
This blog reflect our own views and do not necessarily represent the views of our current or previous employers.
The contents of this blog are from our experience, you may use at your own risk, however you are strongly advised to cross reference with Product documentation and test before deploying to production environments.






Recent Comments