MGMTDB is new database instance which is used for storing Cluster Health Monitor (CHM) data. In 11g this was being stored in berkley database but starting Oracle database 12c it is configured as Oracle Database Instance.
In 11g, .bdb files were stored in $GRID_HOME/crf/db/hostname and used to take up lot of space (>100G) due to bug in 11.2.0.2
During 12c Grid infrastructure installation, there is option to configure Grid Infrastructure Management Repository.
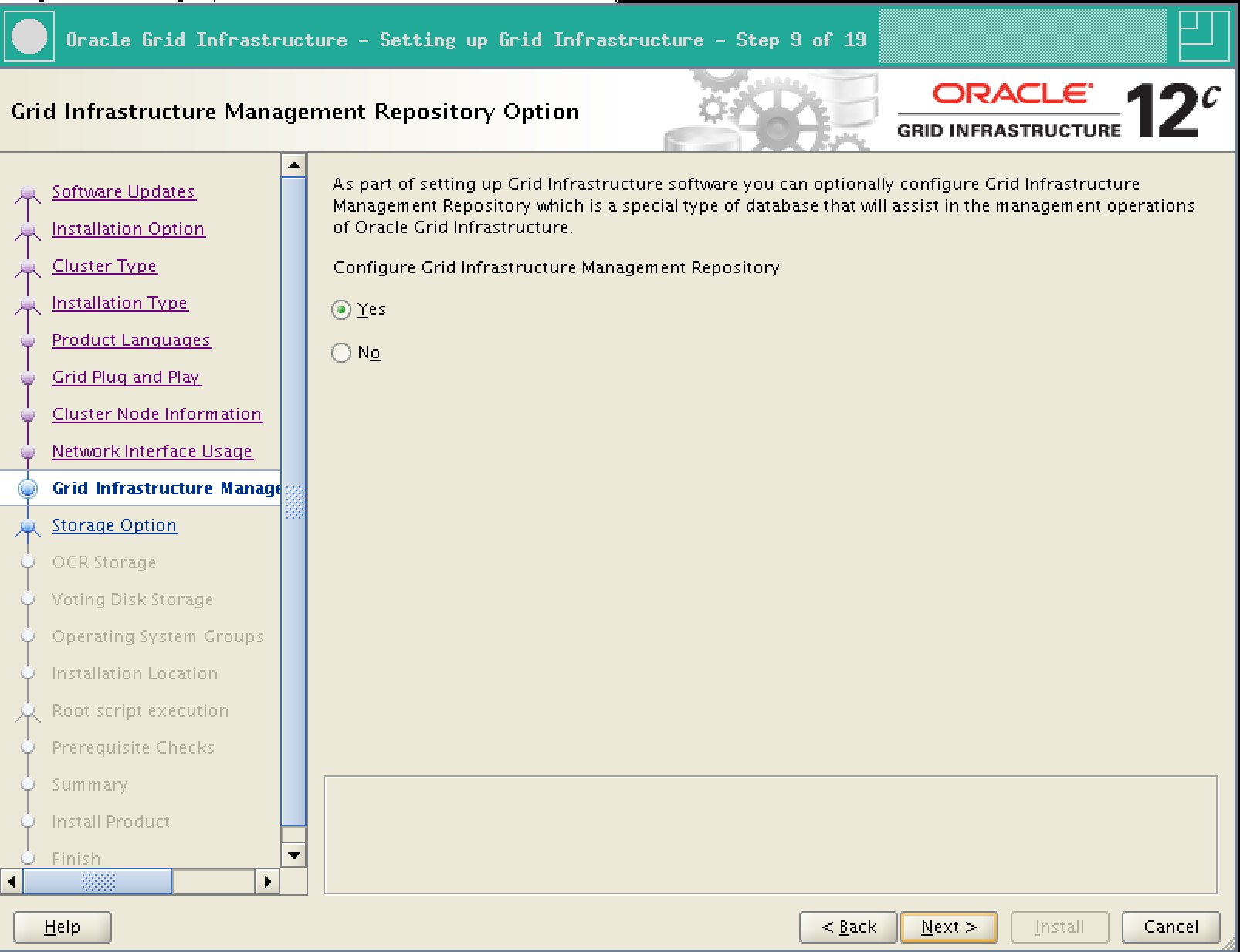
If you choose YES, then you will see instance -MGMTDB running on one of the node on your cluster.
[oracle@oradbdev02]~% ps -ef|grep mdb_pmon oracle 7580 1 0 04:57 ? 00:00:00 mdb_pmon_-MGMTDB
This is a Oracle single instance which is being managed by Grid Infrastructure and fails over to surviving node if existing node crashes.You can identify the current master using below command
-bash-4.1$ oclumon manage -get MASTER Master = oradbdev02
This DB instance can be managed using srvctl commands. Current master can also be identified using status command
$srvctl status mgmtdb Database is enabled Instance -MGMTDB is running on node oradbdev02
We can look at mgmtdb config using
$srvctl config mgmtdb Database unique name: _mgmtdb Database name: Oracle home: /home/oragrid Oracle user: oracle Spfile: +VDISK/_mgmtdb/spfile-MGMTDB.ora Password file: Domain: Start options: open Stop options: immediate Database role: PRIMARY Management policy: AUTOMATIC Database instance: -MGMTDB Type: Management
Replace config with start/stop to start/stop database.
Databases files for repository database are stored in same location as OCR/Voting disk
SQL> select file_name from dba_data_files union select member file_name from V$logfile; FILE_NAME ------------------------------------------------------------ +VDISK/_MGMTDB/DATAFILE/sysaux.258.819384615 +VDISK/_MGMTDB/DATAFILE/sysgridhomedata.261.819384761 +VDISK/_MGMTDB/DATAFILE/sysmgmtdata.260.819384687 +VDISK/_MGMTDB/DATAFILE/system.259.819384641 +VDISK/_MGMTDB/DATAFILE/undotbs1.257.819384613 +VDISK/_MGMTDB/ONLINELOG/group_1.263.819384803 +VDISK/_MGMTDB/ONLINELOG/group_2.264.819384805 +VDISK/_MGMTDB/ONLINELOG/group_3.265.819384807
We can verify the same using oclumon command
-bash-4.1$ oclumon manage -get reppath CHM Repository Path = +VDISK/_MGMTDB/DATAFILE/sysmgmtdata.260.819384687
Since this is stored at same location as Voting disk, if you have opted for configuring Management database, you will need to use voting disk with size >5G (3.2G+ is being used by MGMTDB). During GI Installation ,I had tried adding voting disk of 2G but it failed saying that it is of insufficient size. Error didnot indicate that its needed for Management repository but now I think this is because of repository sharing same location as OCR/Voting disk.
Default (also Minimum) size for CHM repository is 2048 M . We can increase respository size by issuing following command
-bash-4.1$ oclumon manage -repos changerepossize 4000 The Cluster Health Monitor repository was successfully resized.The new retention is 266160 seconds.
This command internally runs resize command on datafile and we can see that it changed datafile size from 2G to 4G
SQL> select file_name,bytes/1024/1024,maxbytes/1024/1024,autoextensible from dba_data_files; FILE_NAME BYTES/1024/1024 MAXBYTES/1024/1024 AUT -------------------------------------------------- --------------- ------------------ --- +VDISK/_MGMTDB/DATAFILE/sysmgmtdata.260.819384687 4000 0 NO
If we try to reduce the size from 4Gb to 3Gb, it will warn and upon user confirmation drop all repository data
-bash-4.1$ oclumon manage -repos changerepossize 3000 Warning: Entire data in Cluster Health Monitor repository will be deleted.Do you want to continue(Yes/No)? Yes The Cluster Health Monitor repository was successfully resized.The new retention is 199620 seconds.
Tracefiles for db are stored under DIAG_HOME/_mgmtdb/-MGMTDB/trace. Alert log for instance can be found at this location. Since file name start with -MGMTDB*, we need to use ./ to access files. e.g
[oracle@oradbdev02]~/diag/rdbms/_mgmtdb/-MGMTDB/trace% vi -MGMTDB_mmon_7670.trc VIM - Vi IMproved 7.2 (2008 Aug 9, compiled Feb 17 2012 10:23:31) Unknown option argument: "-MGMTDB_mmon_7670.trc" More info with: "vim -h" [oracle@oradbdev02]~/diag/rdbms/_mgmtdb/-MGMTDB/trace% vi ./-MGMTDB_mmon_7670.trc
Sample output from a 3 node RAC setup
[oracle@oradbdev02]~% oclumon dumpnodeview -allnodes ---------------------------------------- Node: oradbdev02 Clock: '13-07-23 07.19.00' SerialNo:1707 ---------------------------------------- SYSTEM: #pcpus: 4 #vcpus: 4 cpuht: N chipname: Dual-Core cpu: 5.15 cpuq: 1 physmemfree: 469504 physmemtotal: 7928104 mcache: 5196464 swapfree: 8191992 swaptotal: 8191992 hugepagetotal: 0 hugepagefree: 0 hugepagesize: 2048 ior: 0 iow: 51 ios: 9 swpin: 0 swpout: 0 pgin: 134 pgout: 140 netr: 223.768 netw: 176.523 procs: 461 rtprocs: 25 #fds: 24704 #sysfdlimit: 779448 #disks: 6 #nics: 3 nicErrors: 0 TOP CONSUMERS: topcpu: 'oraagent.bin(7090) 2.59' topprivmem: 'java(7247) 149464' topshm: 'ora_mman_snowy1(7783) 380608' topfd: 'ocssd.bin(6249) 273' topthread: 'crsd.bin(6969) 42' ---------------------------------------- Node: oradbdev03 Clock: '13-07-23 07.19.02' SerialNo:47 ---------------------------------------- SYSTEM: #pcpus: 4 #vcpus: 4 cpuht: N chipname: Dual-Core cpu: 3.65 cpuq: 2 physmemfree: 1924468 physmemtotal: 7928104 mcache: 4529232 swapfree: 8191992 swaptotal: 8191992 hugepagetotal: 0 hugepagefree: 0 hugepagesize: 2048 ior: 1 iow: 83 ios: 17 swpin: 0 swpout: 0 pgin: 45 pgout: 55 netr: 67.086 netw: 55.042 procs: 373 rtprocs: 22 #fds: 21280 #sysfdlimit: 779448 #disks: 6 #nics: 3 nicErrors: 0 TOP CONSUMERS: topcpu: 'osysmond.bin(19281) 1.99' topprivmem: 'ocssd.bin(19323) 83528' topshm: 'ora_mman_snowy2(20306) 261508' topfd: 'ocssd.bin(19323) 249' topthread: 'crsd.bin(19617) 40' ---------------------------------------- Node: oradbdev04 Clock: '13-07-23 07.18.58' SerialNo:1520 ---------------------------------------- SYSTEM: #pcpus: 4 #vcpus: 4 cpuht: N chipname: Dual-Core cpu: 3.15 cpuq: 1 physmemfree: 1982828 physmemtotal: 7928104 mcache: 4390440 swapfree: 8191992 swaptotal: 8191992 hugepagetotal: 0 hugepagefree: 0 hugepagesize: 2048 ior: 0 iow: 25 ios: 4 swpin: 0 swpout: 0 pgin: 57 pgout: 27 netr: 81.148 netw: 41.761 procs: 355 rtprocs: 24 #fds: 20064 #sysfdlimit: 779450 #disks: 6 #nics: 3 nicErrors: 0 TOP CONSUMERS: topcpu: 'ocssd.bin(6745) 2.00' topprivmem: 'ocssd.bin(6745) 83408' topshm: 'ora_mman_snowy3(8168) 381768' topfd: 'ocssd.bin(6745) 247' topthread: 'crsd.bin(7202) 40'
You can learn more about oclumon usage by referring to Oclumon Command Reference
I faced error in my setup where I was getting ora-28000 error while using oclumon command. I tried unlocking account and it didn’t succeed.
oclumon dumpnodeview dumpnodeview: Node name not given. Querying for the local host CRS-9118-Grid Infrastructure Management Repository connection error ORA-28000: the account is locked SQL> alter user chm account unlock; User altered. dumpnodeview: Node name not given. Querying for the local host CRS-9118-Grid Infrastructure Management Repository connection error ORA-01017: invalid username/password; logon denied
This issue occurred as post configuration tasks had failed during GI installation. Solution is to run mgmtca from grid home which fixed the issue by unlocking and setting password for users. Wallet was configured for oclumon to be able to access the repository without hard coding password.
[main] [ 2013-07-23 05:32:41.619 UTC ] [Mgmtca.main:102] Running mgmtca [main] [ 2013-07-23 05:32:41.651 UTC ] [Mgmtca.execute:192] Adding internal user1 [main] [ 2013-07-23 05:32:41.653 UTC ] [Mgmtca.execute:194] Adding internal user2 [main] [ 2013-07-23 05:32:42.028 UTC ] [Mgmtca.isMgmtdbOnCurrentNode:306] Management DB is running on blr-devdb-003local node is blr-devdb-003 [main] [ 2013-07-23 05:32:42.074 UTC ] [MgmtWallet.createWallet:54] Wallet created [main] [ 2013-07-23 05:32:42.084 UTC ] [Mgmtca.execute:213] MGMTDB Wallet created [main] [ 2013-07-23 05:32:42.085 UTC ] [Mgmtca.execute:214] Adding user/passwd to MGMTDB Wallet [main] [ 2013-07-23 05:32:42.210 UTC ] [MgmtWallet.terminate:122] Wallet closed [main] [ 2013-07-23 05:32:42.211 UTC ] [Mgmtca.execute:227] Unlocking user and setting password in database [main] [ 2013-07-23 05:32:42.211 UTC ] [Mgmtjdbc.connect:66] Connection String=jdbc:oracle:oci:@(DESCRIPTION=(ADDRESS=(PROTOCOL=beq)(PROGRAM=/home/oragrid/bin/oracle)(ARGV0=oracle-MGMTDB)(ARGS='(DESCRIPTION=(LOCAL=YES)(ADDRESS=(PROTOCOL=beq)))')(ENVS='ORACLE_HOME=/home/oragrid,ORACLE_SID=-MGMTDB'))) [main] [ 2013-07-23 05:32:42.823 UTC ] [Mgmtjdbc.connect:72] Connection Established
These are two internal users being referred above
select username,account_status from dba_users where username like 'CH%'; USERNAME ACCOUNT_STATUS ------------------------------ -------------------------------- CHM OPEN CHA OPEN


Recent Comments