Last week Oracle released 12c database and Oracle blogosphere is bustling with lot of people posting details about new versions and setup.
I too decided to take plunge and setup my own RAC cluster. I had 4 machines with me but no shared storage 🙁
Long back I had done one installation using openfiler (Followed Jeff Hunter’s article on OTN) but in that case we installed openfiler software on base machine. Finally I decided to try installing it on Virtualbox.
I checked openfiler website and found out that they provide templates for VM which meant that installation on VM was supported. (Anyways this is my test setup 🙂 )
This was 64 bit machine, So I downloaded 64 bit rpm Virtualbox software.
When you try to install it, this will fail with following error
rpm -i VirtualBox-4.2-4.2.14_86644_el6-1.x86_64.rpm warning: VirtualBox-4.2-4.2.14_86644_el6-1.x86_64.rpm: Header V4 DSA/SHA1 Signature, key ID 98ab5139: NOKEY error: Failed dependencies: libSDL-1.2.so.0()(64bit) is needed by VirtualBox-4.2-4.2.14_86644_el6-1.x86_64
Solution : Install SDL package . You can either install SDL through yum or install same rpm using yum and it will find dependent SDL package and install it for you.
#yum install SDL # rpm -i VirtualBox-4.2-4.2.14_86644_el6-1.x86_64.rpm warning: VirtualBox-4.2-4.2.14_86644_el6-1.x86_64.rpm: Header V4 DSA/SHA1 Signature, key ID 98ab5139: NOKEY Creating group 'vboxusers'. VM users must be member of that group! No precompiled module for this kernel found -- trying to build one. Messages emitted during module compilation will be logged to /var/log/vbox-install.log. WARNING: Deprecated config file /etc/modprobe.conf, all config files belong into /etc/modprobe.d/. Stopping VirtualBox kernel modules [ OK ] Recompiling VirtualBox kernel modules [ OK ] Starting VirtualBox kernel modules [ OK ]
Add oracle user to vboxusers to allow oracle user to manage VM
usermod -G vboxusers oracle
Once done, you can download openfiler software from http://www.openfiler.com/community/download/. You can get direct link for 64 bit binary at Sourceforge.net
Let’s Build Virtual Machine for our setup.
1. Start virtualbox GUI by issuing virtualbox on command line
2. Click on New VM and choose OS (Linux) and Version (Red Hat 64 bit, change it based on your OS)
3. Allocate memory to Machine. I opted for 3G
4. Create a virtual drive of 30G and use .VDI as format. Even though usage is less then 8G, openfiler install fails if you create 8G disk.
5. Once done, click finish and click on settings.
6. Choose Network as eth0 and Bridged adapter. We are using single adapter here
7. Modify Boot order and remove floppy.Keep hard disk as first option
8. In System storage, You can add additional hard disk (Say 100G) which will be used to setup ASM devices
You can use screenshots from oracle-base 12c install article . Note that we are using single adapter and Bridged adapter.
8. When you start VM, it will ask you to choose start-up disk. Choose your openfiler.iso image
9. Press enter on boot screen and then click next

10. Choose install language
11. Next choose hard disk which will be used for installing software. Choose 30G disk which we allocated earlier. Uncheck the second disk
12. Next screen is network configuration. This is most important screen. I used static IP configuration , click edit for eth0 and put all required information i.e IP,subnet,gateway.Also add hostname and DNS information here.

13. Next select timezone and set root password. Once done, you will get success message and reboot will be done. If everything is successful, you can find your setup at
https://hostname:446/ (note its https and not http)
If this doesn’t work then look at your ip settings and ensure that your ip is pingable from outside. More troubleshooting for GUI can be done by restarting openfiler and httpd service. If it gives error, you can troubleshoot further
service openfiler restart service httpd restart
You can configure openfiler ASM volumes by following Jeff Hunter article
In case you are on RHEL6, udev rules mentioned in above link will not work. Frits Hoogland article will be of help here (http://fritshoogland.wordpress.com/2012/07/23/using-udev-on-rhel-6-ol-6-to-change-disk-permissions-for-asm/)
You should be ready with ASM storage and can proceed with RAC install. There is not much difference in 12c install except that we have new feature called Oracle ASM Flex. I am documenting screenshots for same here
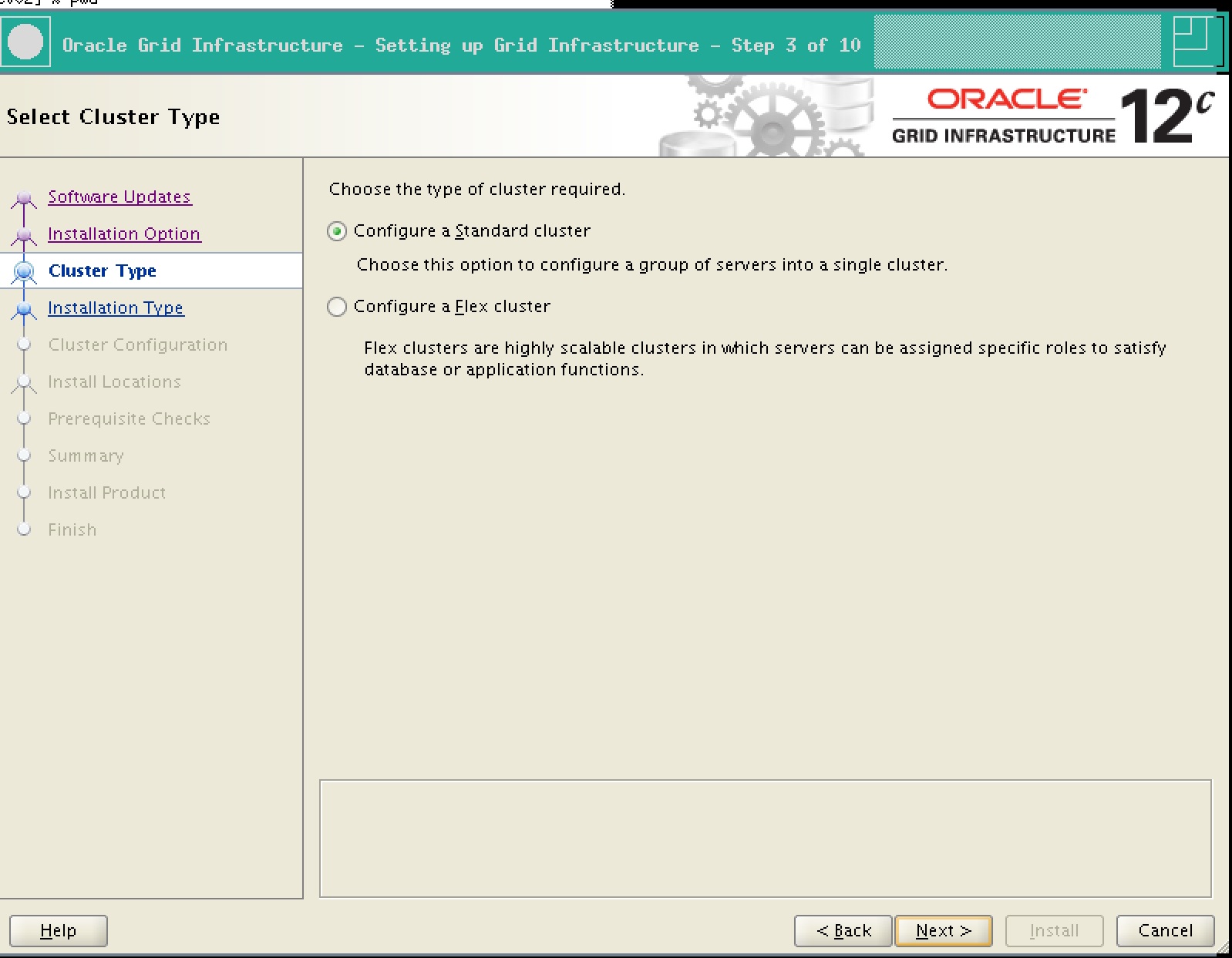
1. Choose Standard Cluster here. If you choose Flex cluster, it would force you to use GNS as option can’t be unchecked.
2. Choose Advanced Install
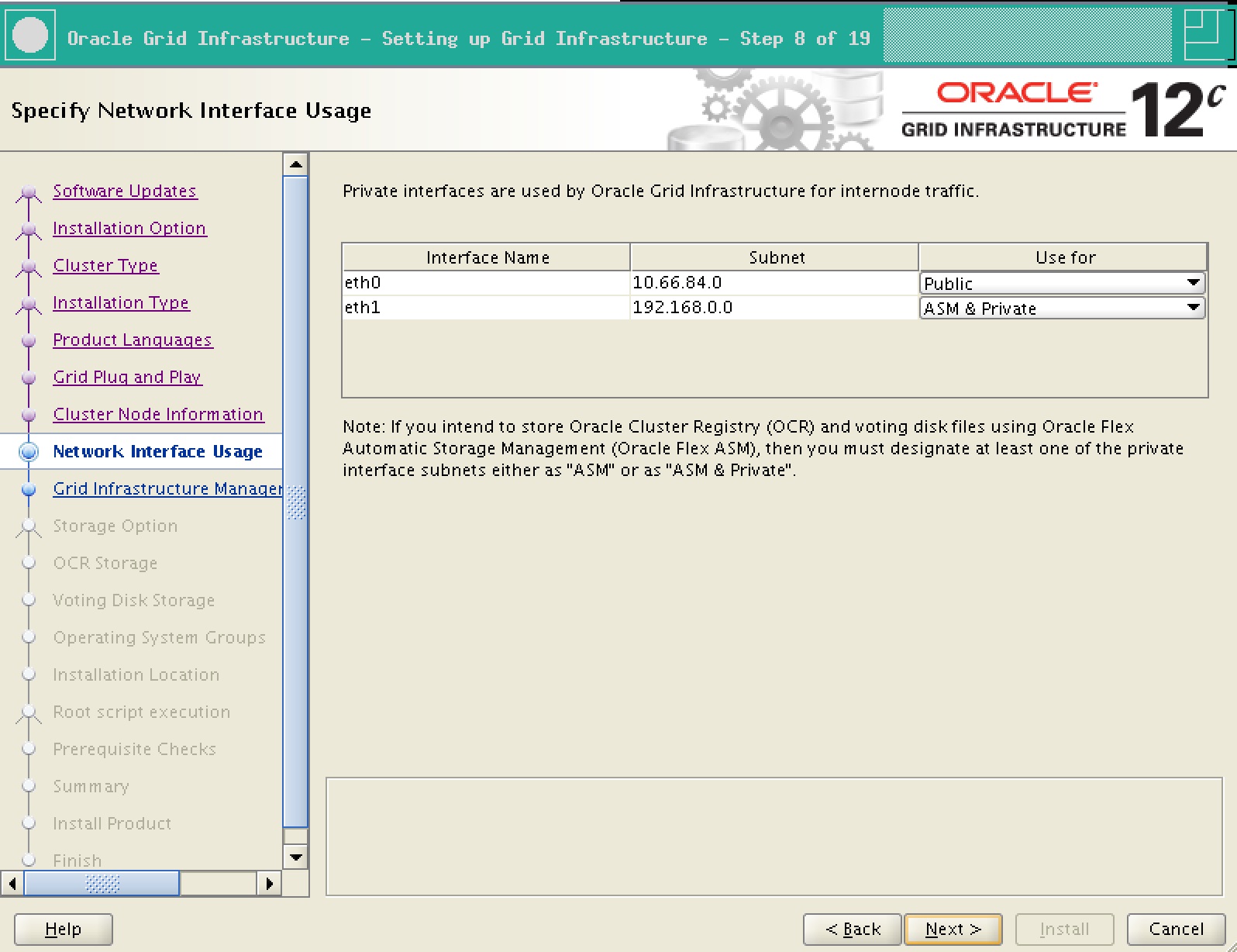
3. When choosing network interface, select ASM and private for private interface
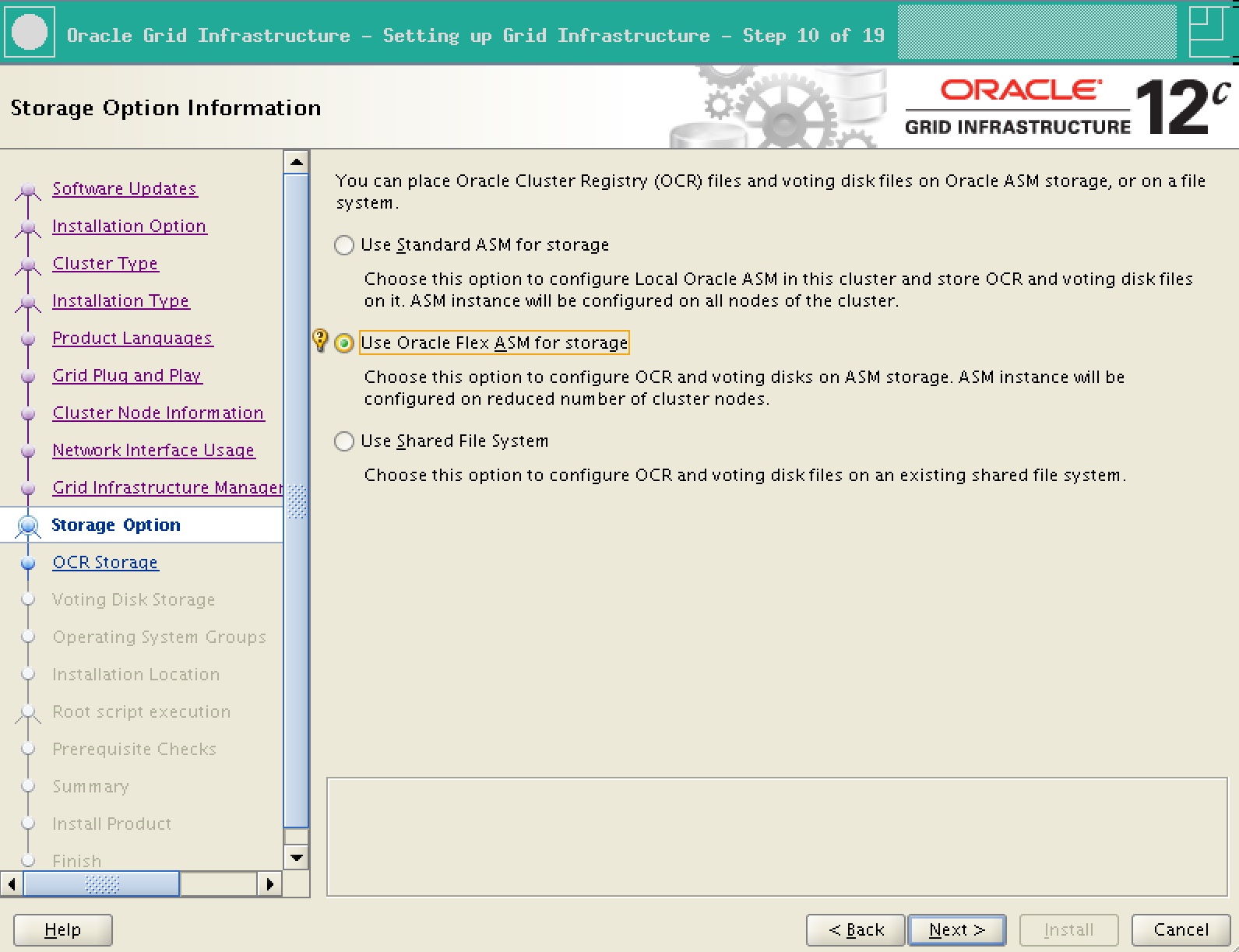
4. On screen 10, choose Oracle Flex ASM
I did two Flex cluster setup with 3 node RAC and 2 node RAC and it seems to work at both places. Let’s see Flex cluster in action
You can verify if your ASM is enabled to use Flex mode using below command
[oracle@oradbdev02]~% asmcmd showclustermode ASM cluster : Flex mode enabled
crsctl command can be used to set Flex mode later. Below command will show configuration
oracle@oradbdev02]~% srvctl config asm ASM home: /home/oragrid Password file: +VDISK/orapwASM ASM listener: LISTENER ASM instance count: 3 Cluster ASM listener: ASMNET1LSNR_ASM [oracle@oradbdev02]~% srvctl status asm -detail ASM is running on oradbdev02,oradbdev03,oradbdev04 ASM is enabled.
Lets reduce the ASM to run only on 2 nodes.This will stop ASM on one node
oracle@oradbdev02]~% srvctl modify asm -count 2 [oracle@oradbdev02]~% srvctl status asm -detail ASM is running on oradbdev02,oradbdev03 ASM is enabled.
There is no ASM on node oradbdev04 but db is still running
[oracle@oradbdev04]~% ps -ef|grep pmon oracle 3949 1 0 10:27 ? 00:00:00 ora_pmon_snowy3 oracle 18728 1 0 07:59 ? 00:00:01 apx_pmon_+APX3
If you now try to start ASM on 3rd node, it will give error
[oracle@oradbdev02]~% srvctl config asm ASM home: /home/oragrid Password file: +VDISK/orapwASM ASM listener: LISTENER ASM instance count: 2 Cluster ASM listener: ASMNET1LSNR_ASM [oracle@oradbdev02]~% srvctl start asm -n oradbdev04 PRCR-1013 : Failed to start resource ora.asm PRCR-1064 : Failed to start resource ora.asm on node oradbdev04 CRS-2552: There are no available instances of resource 'ora.asm' to start.
Lets make it count back to 3 and ASM will start now
[oracle@oradbdev02]~% srvctl modify asm -count 3 [oracle@oradbdev02]~% srvctl start asm -n oradbdev04 [oracle@oradbdev02]~% srvctl status asm -detail ASM is running on oradbdev02,oradbdev03,oradbdev04 ASM is enabled.
Now need to explore some other new feature




























Recent Comments