There could be a scenario of node crash due to OS/hardware issues and a reinstall/reimage of the same. In such cases, just a normal node addition would not help since the OCR still contain the references of original node. We need to remove them first and then perform a node addition.
– Voting disk and OCR are on ASM( ASMLIB is being used to manage the shared disks )
– After the OS reinstall, user equivalence has been set and all required packages have been installed along with setup of ASMLIB
– The crashed node was node2
STEPS
———- 1. Clearing the OCR entries for re-imaged host.
# crsctl delete node -n node2
To verify the success of above step, execute “olsnodes” on surviving node and the reimaged host shouldnot show up in list.
2. Remove the VIP information of reimaged host from OCR
Execute the following on existing node :
/u01/grid/11.2/bin/srvctl remove vip -i node2-v -f
3. Clear the inventory for reimaged host for GI and DB Homes.
In my case, the above command came out without giving any messages. Actually the addNode.sh didnot run at all.
Cause : Since ASMLIB is in use, we had hit the issue discussed in MOS Note : 1267569.1
The error seen in step 4 helped in finding this.
Solution :
Set the following parameters and run addNode.sh again.
IGNORE_PREADDNODE_CHECKS=Y
export IGNORE_PREADDNODE_CHECKS
[oracle@node1] /u01/grid/11.2/oui/bin% ./addNode.sh -silent "CLUSTER_NEW_NODES={node2}" "CLUSTER_NEW_VIRTUAL_HOSTNAMES={node2-v}"
Starting Oracle Universal Installer...
Checking swap space: must be greater than 500 MB. Actual 12143 MB
Performing tests to see whether nodes node2 are available
............................................................... 100% Done.
Cluster Node Addition Summary
Global Settings
Source: /u01/grid/11.2
New Nodes
Space Requirements
New Nodes
node2
Instantiating scripts for add node (Tuesday, December 21, 2010 3:35:16 AM PST)
. 1% Done.
Instantiation of add node scripts complete
Copying to remote nodes (Tuesday, December 21, 2010 3:35:18 AM PST)
............................................................................................... 96% Done.
Home copied to new nodes
Saving inventory on nodes (Tuesday, December 21, 2010 3:37:57 AM PST)
. 100% Done.
Save inventory complete
WARNING:
The following configuration scripts need to be executed as the "root" user in each cluster node.
/u01/grid/11.2/root.sh # On nodes node2
To execute the configuration scripts:
1. Open a terminal window
2. Log in as "root"
3. Run the scripts in each cluster node
The Cluster Node Addition of /u01/grid/11.2 was successful.
Please check '/tmp/silentInstall.log' for more details.
6. Run root.sh on reimaged node to start up CRS stack.
This will completed Grid Infrastucture setup on the node.
7. Proceed to run addNode.sh for DB Home( on existing Node)
11.2.0.2 Patchset was released few days back. I decided to upgrade a test RAC database to 11.2.0.2 yesterday and was able to do it successfully. I will be documenting the steps here for easy reference
Environment Details
2 node RAC on Red Hat Enterprise Linux AS release 4 (Nahant Update 8), 64 bit
To upgrade existing 11.2.0.1 Oracle Grid Infrastructure installations to Oracle Grid Infrastructure 11.2.0.2, you must first do at least one of the following:
– Patch the release 11.2.0.1 Oracle Grid Infrastructure home with the fix for bug 9413827.
– Install Oracle Grid Infrastructure Patch Set 1 (GIPS1) or Oracle Grid Infrastructure Patch Set 2 (GIPS2).
I will be using Oracle Grid Infrastructure Patch set 2.
Software and Patches
1) Download Patch 9655006 – 11.2.0.1.2 for Grid Infrastructure (GI) Patch Set Update from MOS
Unzip the zip file and copy OPatch folder to $ORACLE_HOME by renaming the earlier OPatch directory. You can refer to How To Download And Install OPatch [ID 274526.1]
Apply Grid Infrastructure (GI) Patch Set Update – 9655006
It applies patch 9654983 and 9655006 to both Database and Grid home. We proceed by checking for any patch conflicts
[oracle@oradbdev01]~/software/11.2.0.2/psu% opatch prereq CheckConflictAgainstOHWithDetail -phBaseDir ./9655006
Invoking OPatch 11.2.0.1.3
Oracle Interim Patch Installer version 11.2.0.1.3
Copyright (c) 2010, Oracle Corporation. All rights reserved.
PREREQ session
Oracle Home : /oracle/product/app/11.2.0/dbhome_1
Central Inventory : /oracle/oraInventory
from : /etc/oraInst.loc
OPatch version : 11.2.0.1.3
OUI version : 11.2.0.1.0
OUI location : /oracle/product/app/11.2.0/dbhome_1/oui
Log file location : /oracle/product/app/11.2.0/dbhome_1/cfgtoollogs/opatch/opatch2010-10-02_06-03-34AM.log
Patch history file: /oracle/product/app/11.2.0/dbhome_1/cfgtoollogs/opatch/opatch_history.txt
Invoking prereq "checkconflictagainstohwithdetail"
Prereq "checkConflictAgainstOHWithDetail" passed.
OPatch succeeded.<span style="font-family: Georgia, 'Times New Roman', 'Bitstream Charter', Times, serif; font-size: small;"><span style="line-height: 19px; white-space: normal;">
</span></span>
We need to use opatch auto to patch both Grid Infrastructure and RAC database home.It can be used to patch separately but I am going with patching both. This is great improvement over 10g CRS patch bundles as it had lot of steps to be run as root or oracle software owner. ( I had myself messed up once by running a command as root instead of oracle 🙁 ) Opatch starts with patching the database home and then patches the grid infrastructure home. You can stop the database instance running out of oracle home.(opatch asks for shutting down database, so in case you do not stop,don’t worry it will warn)
Note: In case you are on RHEL5/OEL5 and using ACFS for database volumes, it is recommended to use opatch auto <loc> -oh <grid home> to first patch the Grid home instead of patching them together
Unzip patch 965506 to directory say /oracle/software/gips2.It will create two directories for patch 9654983 and 9655006. Connect as root user and set the oracle home and Opatch directory . Stop the database instance running on the node
srvctl stop instance -d db11g -i db11g1
Next run opatch auto command as root
#opatch auto /oracle/software/gips2
Oracle Interim Patch Installer version 11.2.0.1.3
Copyright (c) 2010, Oracle Corporation. All rights reserved.
UTIL session
Oracle Home : /oracle/product/grid
Central Inventory : /oracle/oraInventory
from : /etc/oraInst.loc
OPatch version : 11.2.0.1.3
OUI version : 11.2.0.1.0
OUI location : /oracle/product/grid/oui
Log file location : /oracle/product/grid/cfgtoollogs/opatch/opatch2010-10-02_06-35-03AM.log
Patch history file: /oracle/product/grid/cfgtoollogs/opatch/opatch_history.txt
Invoking utility "napply"
Checking conflict among patches...
Checking if Oracle Home has components required by patches...
Checking conflicts against Oracle Home...
OPatch continues with these patches: 9654983
Do you want to proceed? [y|n]
y
User Responded with: Y
Running prerequisite checks...
Provide your email address to be informed of security issues, install and
initiate Oracle Configuration Manager. Easier for you if you use your My
Oracle Support Email address/User Name.
Visit http://www.oracle.com/support/policies.html for details.
Email address/User Name:
You have not provided an email address for notification of security issues.
Do you wish to remain uninformed of security issues ([Y]es, [N]o) [N]: Y
You selected -local option, hence OPatch will patch the local system only.
Please shutdown Oracle instances running out of this ORACLE_HOME on the local system.
(Oracle Home = '/oracle/product/grid')
Is the local system ready for patching? [y|n]
y
User Responded with: Y
Backing up files affected by the patch 'NApply' for restore. This might take a while...
I have not copied the whole output. It asks you to specify MOS credentials for setting up Oracle Configuration Manager. You can skip it as mentioned above. You will find following errors in the end
OPatch succeeded.
ADVM/ACFS is not supported on Redhat 4
Failure at scls_process_spawn with code 1
Internal Error Information:
Category: -1
Operation: fail
Location: canexec2
Other: no exe permission, file [/oracle/product/grid/bin/ohasd]
System Dependent Information: 0
CRS-4000: Command Start failed, or completed with errors.
Timed out waiting for the CRS stack to start.<span style="font-family: Georgia, 'Times New Roman', 'Bitstream Charter', Times, serif; font-size: small;"><span style="line-height: 19px; white-space: normal;">
</span></span>
This is a known issue and discussed in 11.2.0.X Grid Infrastructure PSU Known Issues [ID 1082394.1]
To solve this issue, connect as root user and execute following command from your Grid Infrastructure home
cd $GRID_HOME
# ./crs/install/rootcrs.pl -patch
2010-10-02 06:59:54: Parsing the host name
2010-10-02 06:59:54: Checking for super user privileges
2010-10-02 06:59:54: User has super user privileges
Using configuration parameter file: crs/install/crsconfig_params
ADVM/ACFS is not supported on Redhat 4
CRS-4123: Oracle High Availability Services has been started.
Start oracle database instance on the node which has been patched
srvctl start instance -d db11g -i db11g1
Repeat the above steps for node 2.It took me 40 minutes for each node to complete opatch auto activity.Once it is done,execute following from one node for all databases to complete patch installation
cd $ORACLE_HOME/rdbms/admin
sqlplus /nolog
SQL> CONNECT / AS SYSDBA
SQL> @catbundle.sql psu apply
SQL> QUIT
This completes patching of Grid Infrastructure Patch or PSU2.
Upgrading Grid Infrastructure home to 11.2.0.2
Ensure following environment variables are not set :ORA_CRS_HOME; ORACLE_HOME; ORA_NLS10; TNS_ADMIN
Strating with 11.2.0.2, Grid infrastructure (Clusterware and ASM Home) upgrade is out of place upgrade i.e we install in new ORACLE_HOME. Unlike database home we cannot perform an in-place upgrade of Oracle Clusterware and Oracle ASM to existing homes.
Unset following variables too
$ unset ORACLE_BASE
$ unset ORACLE_HOME
$ unset ORACLE_SID
Relax permissions for GRID_HOME
#chmod -R 755 /oracle/product/grid
#chown -R oracle /oracle/product/grid
#chown oracle /oracle/product
Start the runInstaller from the 11.2.0.2 grid software directory.
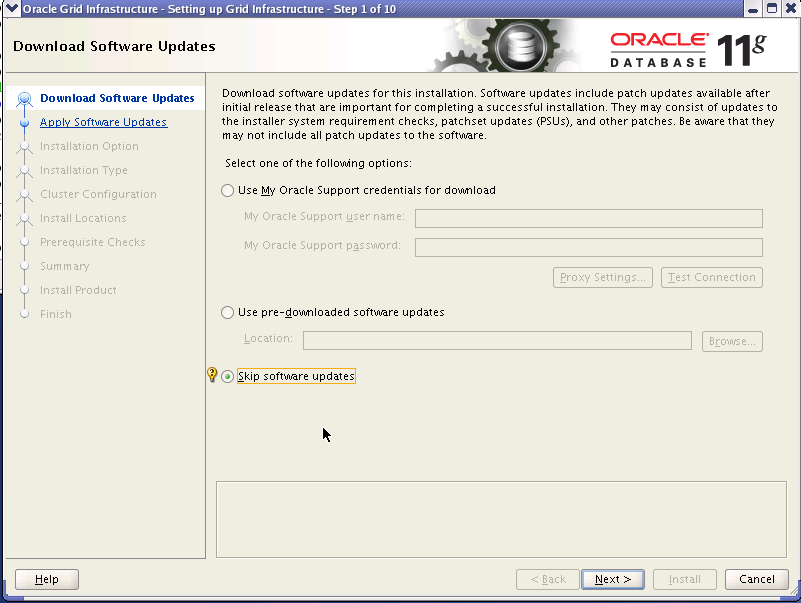
On first screen, it will ask for MOS details. I have chosen skip Software update
Since we are upgrading existing installation, choose “Upgrade Oracle Grid Infrastructure or Oracle Automatic Storage Management”. This will install software and also configure ASM
Next screen displays nodes which OUI will patch
Select the OSDBA,OSASM and OSOPER group. I have chosen dba
Since I have chosen all 3 groups to be same, it gives warning. Select Yes to continue
Specify the grid software installation directory. I have used /oracle/product/oragrid/11.2.0.2 (Better to input release as we will be having out of place upgrades for future patchsets too)
OUI reports some issues with swap size ,shmmax and NTP. You can fix them or choose to ignore. OUI can create a fixup script for you.
Installation starts copying file. After files have been copied to both nodes, it asks for running the rootupgrade.sh script from all nodes
Stop the database instance running from the node at this time and then run script as root. Please note that ASM and clusterware should not be stopped as rootupgrade.sh requires them to be up and takes care of shutting down and starting with new home.In my case, running rootupgrade.sh successfully succeeded on node 1 but it hung on node 2 . I did a cancel and re-ran it. Pasting the contents from node 2 second run
[root@oradbdev02 logs]# /oracle/product/oragrid/11.2.0.2/rootupgrade.sh
Running Oracle 11g root script...
The following environment variables are set as:
ORACLE_OWNER= oracle
ORACLE_HOME= /oracle/product/oragrid/11.2.0.2
Enter the full pathname of the local bin directory: [/usr/local/bin]:
The contents of "dbhome" have not changed. No need to overwrite.
The contents of "oraenv" have not changed. No need to overwrite.
The contents of "coraenv" have not changed. No need to overwrite.
Entries will be added to the /etc/oratab file as needed by
Database Configuration Assistant when a database is created
Finished running generic part of root script.
Now product-specific root actions will be performed.
Using configuration parameter file: /oracle/product/oragrid/11.2.0.2/crs/install/crsconfig_params
clscfg: EXISTING configuration version 5 detected.
clscfg: version 5 is 11g Release 2.
Successfully accumulated necessary OCR keys.
Creating OCR keys for user 'root', privgrp 'root'..
Operation successful.
CRS-1115: Oracle Clusterware has already been upgraded.
ASM upgrade has finished on last node.
Preparing packages for installation...
cvuqdisk-1.0.9-1
Configure Oracle Grid Infrastructure for a Cluster ... succeeded
On clicking next in OUI, it reported that cluvfy has failed and some of components are not installed properly. To verify I ran cluvfy manually. Pasting content for which it failed
./cluvfy stage -post crsinst -n oradbdev01,oradbdev02 -verbose
<span style="font-family: Georgia, 'Times New Roman', 'Bitstream Charter', Times, serif; line-height: 19px; white-space: normal; font-size: 13px;">
<pre style="font: normal normal normal 12px/18px Consolas, Monaco, 'Courier New', Courier, monospace;">-------------------------------truncated output -------------------
ASM Running check passed. ASM is running on all specified nodes
Checking OCR config file "/etc/oracle/ocr.loc"...
ERROR:
PRVF-4175 : OCR config file "/etc/oracle/ocr.loc" check failed on the following nodes:
oradbdev02:Group of file "/etc/oracle/ocr.loc" did not match the expected value. [Expected = "oinstall" ; Found = "dba"]
oradbdev01:Group of file "/etc/oracle/ocr.loc" did not match the expected value. [Expected = "oinstall" ; Found = "dba"]
Disk group for ocr location "+DG_DATA01" available on all the nodes
OCR integrity check failed
-------------------------------truncated output -------------------
Checking OLR config file...
ERROR:
PRVF-4184 : OLR config file check failed on the following nodes:
oradbdev02:Group of file "/etc/oracle/olr.loc" did not match the expected value. [Expected = "oinstall" ; Found = "dba"]
oradbdev01:Group of file "/etc/oracle/olr.loc" did not match the expected value. [Expected = "oinstall" ; Found = "dba"]
Checking OLR file attributes...
ERROR:
PRVF-4187 : OLR file check failed on the following nodes:
oradbdev02:Group of file "/oracle/product/oragrid/11.2.0.2/cdata/oradbdev02.olr" did not match the expected value. [Expected = "oinstall" ; Found = "dba"]
oradbdev01:Group of file "/oracle/product/oragrid/11.2.0.2/cdata/oradbdev01.olr" did not match the expected value. [Expected = "oinstall" ; Found = "dba"]
OLR integrity check failed
-------------------------------truncated output -------------------
Checking NTP daemon command line for slewing option "-x"
Check: NTP daemon command line
Node Name Slewing Option Set?
------------------------------------ ------------------------
oradbdev02 no
oradbdev01 no
Result:
NTP daemon slewing option check failed on some nodes
PRVF-5436 : The NTP daemon running on one or more nodes lacks the slewing option "-x"
Result: Clock synchronization check using Network Time Protocol(NTP) failed
PRVF-9652 : Cluster Time Synchronization Services check failed
We see that cluvfy is reporting error that it expected oinstall group but found dba group. I had not specified install group during installation, so can ignore it.For NTP you can correct it by setting following in ntpd.conf and restart the ntpd daemon
Refer How to Configure NTP to Resolve CLUVFY Error PRVF-5436 PRVF-9652 [ID 1056693.1]
At this moment Grid Infrastructure has been successfully upgraded to 11.2.0.2. Next we will upgrade the RAC database home. You can refer to Steps to Upgrade 11.2.0.1 RAC to 11.2.0.2
Steps for cloning a RAC database with RMAN is similar to cloning a single instance database. But while using rman duplicate in 10g, you will get following errors
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of Duplicate Db command at 06/14/2010 00:09:42
RMAN-03015: error occurred in stored script Memory Script
RMAN-06136: ORACLE error from auxiliary database: ORA-38856: cannot mark instance UNNAMED_INSTANCE_2 (redo thread 2) as enabled
RMAN> exit
This is due to Bug 4355382 ORA-38856: FAILED TO OPEN DATABASE WITH RESETLOGS WHEN USING RAC BACKUP
To avoid this we need to set the following initialization parameter on the auxiliary database; and restart the database in no mount mode
_no_recovery_through_resetlogs=TRUE
Unset this once rman duplicate command completes successfully. One more notable thing which I noticed while cloning this database was that if you use skip readonly clause to skip duplicating read only tablespace, entries for read only tablespace still remain and file names are marked as missing
/oracle/product/10.2/dbs/MISSING00048
OFFLINE READ ONLY
/oracle/product/10.2/dbs/MISSING00049
OFFLINE READ ONLY
SKIP READONLY Excludes datafiles in read-only tablespaces from the duplicate database.
Note: A record for the skipped read-only tablespace still appears in DBA_TABLESPACES. By using this feature, you can activate the read-only tablespace later. For example, you can store the read-only tablespace data on a CD-ROM, then mount the CD-ROM later and view the data
If you don’t plan to make use of these tablespaces, you can drop them by simply using drop tablespace command .Meanwhile do you know that tables can be dropped from read-only tablespace. To know more about it, you can read this entry from Tanel describing this behavior
While performing 11gR2 RAC Database Software installation with response file (silent mode), I got this error.
[SEVERE] - Invalid My Oracle Support credentials
I was using default response files for performing this installation. Searching on MOS (My Oracle Support ), I got a note indicating that following parameter need’s to be specified
I provided a dummy value for these two paramters but the installation again failed with same errors. Then I gave correct credentials and tried again, this time installation was succesful. My initial thought was ” Is Oracle forcing people to have valid MOS account for performing installation” But this couldn’t be true as I had earlier done GUI installation without providing these credentials. It was clear that there was some other parameter which controlled this behavior. So as to diagnose it , I created a response file using GUI (Un checking the check box for my oracle support credentials) . This time response file had two additional parameters
#------------------------------------------------------------------------------
# Specify whether to enable the user to set the password for
# My Oracle Support credentials. The value can be either true or false.
# If left blank it will be assumed to be false.
#
# Example : SECURITY_UPDATES_VIA_MYORACLESUPPORT=true
#------------------------------------------------------------------------------
SECURITY_UPDATES_VIA_MYORACLESUPPORT=false
#------------------------------------------------------------------------------
# Specify whether user wants to give any proxy details for connection.
# The value can be either true or false. If left blank it will be assumed
# to be false.
#
# Example : DECLINE_SECURITY_UPDATES=false
#------------------------------------------------------------------------------
DECLINE_SECURITY_UPDATES=true
We can see that DECLINE_SECUIRTY_UPDATES value is changed from default value of false to true. From 11.2 docs
DECLINE_SECURITY_UPDATES
If the direct connection is unavailable, set this parameter to false if you do not want to configure Oracle Configuration Manager, or do not want to provide any proxy details for the connection. The default is False.
If you do not set MYORACLESUPPORT_USERNAME to any value and you set this parameter to true, the Oracle Configuration Manager is not configured.
So to workaround this problem, we need to set DECLINE_SECURITY_UPDATES=true
During configuration phase of Grid Infrastructure for cluster, CVU failed while performing post-checks.
Following message is displaced in the Installation Log file:
<span style="font-size: small;"><span style="font-family: arial,helvetica,sans-serif;">Checking Single Client Access Name (SCAN)...</span></span>
<span style="font-size: small;"><span style="font-family: arial,helvetica,sans-serif;">WARNING:
<strong>PRVF-5056</strong> : Scan Listener "LISTENER" not running</span></span>
<span style="font-size: small;"><span style="font-family: arial,helvetica,sans-serif;">Checking name resolution setup for "scan-test.abc.com"...</span></span>
<span style="font-size: small;"><span style="font-family: arial,helvetica,sans-serif;">Verification of SCAN VIP and Listener setup failed</span></span>
The LISTENER from Grid Infrastructure home is running fine:
Same error is observerd by manually runnig CVU as:
$ cluvfy comp scan
<span style="font-size: small;"><span style="font-family: arial,helvetica,sans-serif;">Verifying scan
Checking Single Client Access Name (SCAN)...</span></span>
<span style="font-size: small;"><span style="font-family: arial,helvetica,sans-serif;">WARNING:
<strong>PRVF-5056 </strong>: Scan Listener "LISTENER" not running</span></span>
<span style="font-size: small;"><span style="font-family: arial,helvetica,sans-serif;">Checking name resolution setup for "scan-test.abc.com"...
Verification of SCAN VIP and Listener setup failed
Verification of scan was unsuccessful on all the specified nodes.</span></span>
Checking the status of SCAN using SRVCTL gives correct results:
After this, I clicked at the retry button for the CVU post checks and this time it succeeded.
Though it worked fine after this, but still not sure why I have to manually start the SCAN-Listeners !!!!!
I am creating 11gR2 RAC setup for one of my client. Following Oracle documentation for storage, I opted for Oracle ASM and asked storage team for new physical devices.
Storage admin thus provided me with a set of LUNs instead of actual physical device names like /dev/sdcxxx.
Now the major task is to get the actual device name associated with LUNs.
In OEL4 this is easy to get by issuing
This blog reflect our own views and do not necessarily represent the views of our current or previous employers.
The contents of this blog are from our experience, you may use at your own risk, however you are strongly advised to cross reference with Product documentation and test before deploying to production environments.








Recent Comments